V každém sortimentu se občas objeví jednorázový „výstřel“ – třeba když zákazník koupí stovky kusů do vlastní promo-akce nebo firma vykoupí celý kamion zboží. Tyto objemy jsou reálné, ale neopakovatelné a v běžném měsíci výrazně vyčnívají.
Jak na to bude reagovat model?
Graf ukazuje nalezené outlinery nad kompletním datasetem. Je jednoznačně vidět, že i přes vysoký limit na detekci outlinerů jich spousta existuje a jsou výrazně posunuté od průměru. Proto je nutné extrémy detekovat a rozhodnout, co s nimi. Klíčová otázka tedy zní – kde končí „opravdový“ prodej a začíná outlier?
Poznámka: V případě běžného nastavení detekce extrémů se již dostáváme na 1000 outlinerů.

Využívám kombinaci robustního středu (trim-mean), MAD-skóre a percentilového řezu. Prodej, který je současně nad x% percentilem a dál než k × MAD od středu, prohlásím za outlier a oříznu ho na „bezpečný strop“.
MAD-score: |x – median| / MAD
MAD = median absolute deviation
Možnosti nastavení:
Hledání kompromisu
Otázka outlinerů je hodně specifické téma. Podle metrik je jednoznačně nejlepší “střední ořez”. Na druhou stranu, toto nastavení ořízně tisíce špiček, může se dotknout i reálných hodnot a ve výsledku může být kontraproduktivní.
| Metrika | bez ořezu | střední ořez | vysoký ořez | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 30.2608 | 44.5829 | 28.8406 | 42.9816 | 28.7899 | 43.5887 |
| RMSE | 46.1427 | 22.3537 | 48.0208 | 21.3234 | 48.2553 | 21.7787 |
| R² | 0.9012 | 0.9141 | 0.8904 | |||
| MAPE | 60.0505 | 58.8268 | 56.4778 | |||
| ROBUST | 0.4948 | 62.2027 | 0.5001 | 61.8983 | 0.4874 | 62.6898 |
| STABLE | 0.365 | 0.3482 | 0.3718 | |||
Rozhodnutí:
Po vizuální kontrole jsem zvolil opatrný přístup – řezat jen nejvyšší výstřely. Model tak nepřijde o důležité sezónní signály a metriky sice o chlup ztratí, ale predikce zůstane věrnější reálnému chování zboží.
Raději jsem akceptoval o bod vyšší WAPE než riskovat, že „useknu“ polovinu vánoční poptávky.

Vedle extrémů v obratu (outliners) se v datech objevuje i opačný problém: kategorie jen s několika položkami
Proč to škodí modelu?
Při tréninku deep-learningu každá kategorie dostává embedding vektor (vektor zobrazuje podobnost mezi kategoriemi). U skupiny jen s několika položkami se vektor učí z prakticky nulového vzorku:
Řešení
Embeddingy tak vznikají jen pro kategorie, které mají aspoň několik položek – model dostane méně vektorů, ale informačně bohatší. Navíc se sníží nárok na VRAM.
Když už jsem měl data vyčištěná a obohacená o smysluplné features, čekala mě ještě druhá půlka práce — přesvědčit neuronku, aby se učila správným způsobem. V praxi to připomíná nastavování kávovaru: stejná zrna + stejná voda, ale drobné rozdíly v teplotě či tlaku udělají chuťový zázrak.
Moderní deep-learningový model má řádově více parametrů než klasické algoritmy a desítky hyperparametrů k ladění. Jejich finální nastavení vždy vychází z charakteru dat (sezónnost, promo, long-tail) a z toho, co chceme reálně získat (minimalizovat vyprodání, zmenšit zásoby, odhadnout nejistotu).
Několik základních parametrů:
V tomto kroku jsem uzavřel přípravnou fázi a model poprvé otestoval na scénáři 2
| Metrika | Hodnota (ALL) | Hodnota (Item) |
|---|---|---|
| WAPE | 28.4178 | 42.0787 |
| RMSE | 46.3156 | 21.1877 |
| R² | 0.9004 | |
| MAPE | 52.4587 | |
| ROBUST | 0.4986 | 59.7858 |
| STABLE | 0.3677 |
Výsledky potvrzují, že kombinace rozšířených features a kontroly extrémů přináší první reálně použitelné výsledky – predikce jsou stabilnější, a především lépe zachycují trend i absolutní úroveň poptávky.
Při vizuální kontrole se však ukázalo, že i po všech těchto úpravách přetrvávají tři specifické typy položek, na kterých model stále tápe:
| Typ položky | Projevy | Proč je to problém |
|---|---|---|
| Sezónní prodeje | 10 měsíců nulový prodej, pak se prodá hodně | Model tlumí špičku jako šum |
| Nulové predikce | Nepravidelné prodeje, časté nuly | Predikce sklouzává k nule |
| Slevové akce | Promo zvedá prodej pouze o jednotky % | Slevové akce se řádně v predikci neprojeví |
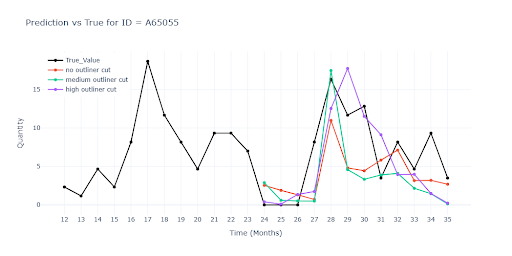
Graf prezentuje typickou prezentaci sezónního zboží. Model není schopen plně simulovat tuto sezónnost bez další pomoci.
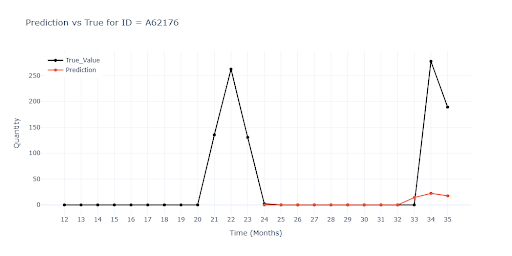
U několika typů položek, nejčastěji se jednalo o položky s nízkým obratem a hodně nulami, model neustále predikoval nuly.
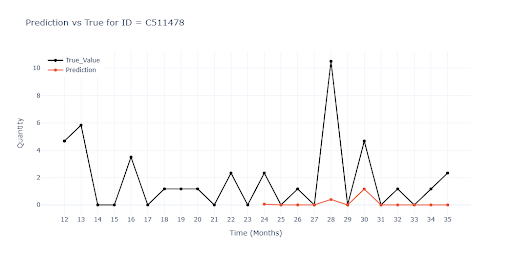
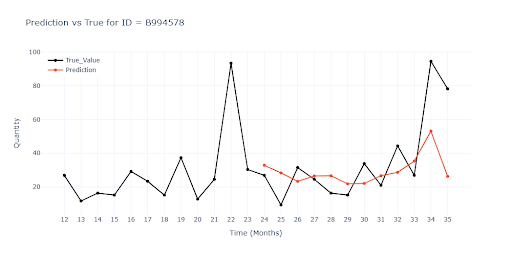
Tento graf zobrazuje špatnou reakci na slevové akce. Měsíce 34 a 35 byli označeny jako slevová akce (stejně jako v předchozích letech). Model na tyto slevy reagoval velmi vlažně.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays