Chvíle pravdy: Jak se model zachová, když ho pustíme na všech 15 000 položek? Nastavení modelu a dat (podle dosavadních zjištění):
Pro závěrečný test jsem zvolil model s group features, ale bez syntetických dat. Tento setup se ukázal jako nejstabilnější napříč celým sortimentem, i když syntetika zůstává zajímavou možností pro budoucí projekty nebo specifické subsety zboží.
| Metrika | Celá historie | 33 měsíců | 13-32 měsíců | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 30.1022 | 49.7127 | 28.1069 | 41.6723 | 33.4304 | 40.1634 |
| RMSE | 45.907 | 22.3895 | 50.4051 | 23.9145 | 26.3204 | 17.0358 |
| R² | 0.9232 | 0.93 | 0.7245 | |||
| MAPE | 65.5438 | 57.332 | 60.9407 | |||
| ROBUST | 0.551 | 72.2735 | 0.5498 | 58.7128 | 0.5049 | 66.3819 |
| STABLE | 0.3884 | 0.3642 | 0.5422 | |||
| Metrika | 6-12 měsíců | 1-6 měsíců | bez historie | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 38.5444 | 45.8518 | 44.6778 | 47.1055 | 80.7317 | 220.7146 |
| RMSE | 26.6287 | 17.1458 | 43.1306 | 27.5178 | 95.9705 | 61.587 |
| R² | 0.7529 | 0.7451 | -0.1913 | |||
| MAPE | 64.676 | 79.1142 | 186.139 | |||
| ROBUST | 0.5233 | 66.5118 | 0.5441 | 89.7998 | 0.4013 | 250.967 |
| STABLE | 0.4801 | 0.4776 | 0.9196 | |||
Výsledky podle délky historie:
Ve srovnání s kapitolou #9 (test na částečném datasetu) jsou metriky prakticky totožné – model drží stabilitu i při trojnásobném objemu dat. Vidět je i mírné zlepšení u SKU s krátkou historií, hlavně díky většímu počtu kategorií v rámci skupin → bohatší data pro embeddingy → lepší přenos vzorů.
Porovnávám predikce modelu z částečného datasetu (minulá kapitola) s novou predikcí nad plným datasetem.
Největší vizuální rozdíly jsou patrné u SKU s krátkou historií – právě tam teď hrají skupinové informace výraznější roli. U delších historií se křivky překrývají téměř dokonale, což potvrzuje, že navýšení tréninkového datasetu na plný rozsah nepoškodilo výkon u zavedených položek.
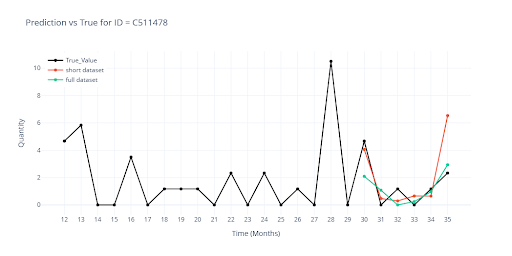
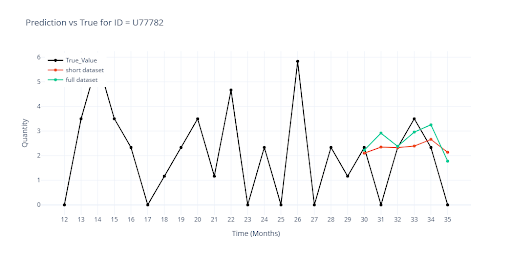
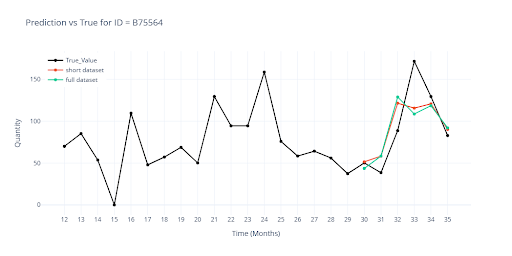

Model si na plném datasetu vede velmi dobře, proto jsem ještě ověřil, jak zvládá promo kampaně. V tréninkových datech dostává informaci kdy a jak dlouho bylo konkrétní zboží ve slevě. V rámci feature engineeringu navíc přidávám kontext:
Vizualizace ukazuje rozdíl v predikci když položka měla plánovanou slevu vs bez slevy.
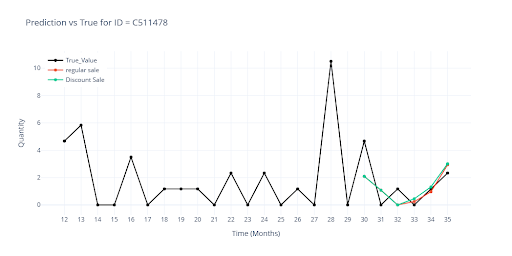
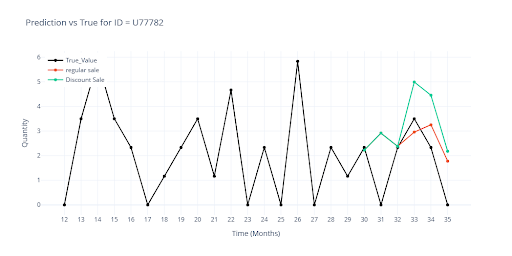
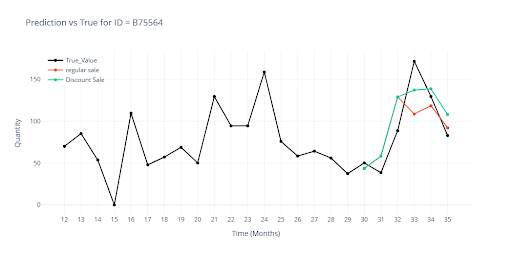
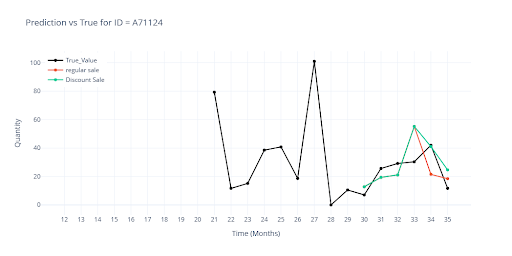
To ukazuje, že model se dokáže rozhodovat podle skutečného dopadu promo akcí v historii a sleva sama o sobě není univerzálním spouštěčem zvýšeného prodeje.
Abych zákazníkovi dodal plnohodnotné řešení, natrénoval jsem finální verzi modelu – tentokrát na celé historii 42 měsíců (od začátku projektu nějaké měsíce uplynuly).
Validační okno tentokrát neexistuje, takže hodnocení probíhá vizuálním porovnáním s interním forecastem zákazníka a skutečnými prodeji (které jsem dohrál zpětně). I když chybí přesná metrika, klíčové je, že zákazník je spokojený a v projektu vidí jednoznačný přínos.
Co ukazuje vizualizační aplikace:
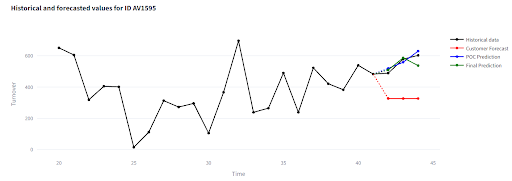

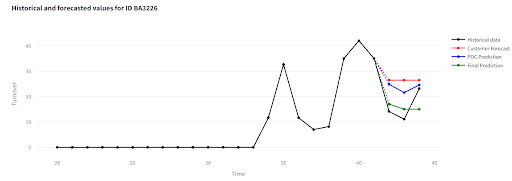
Vyzkoušejte si výsledky sami: https://demo-inventory-forecasts.streamlit.app/.
(Pokud aplikace spí, klikněte na “Yes, get this app back up!” – do minuty naskočí.)
Poznámka: všechny zobrazené údaje jsou anonymizované a lehce pozměněné.
Po deseti dílech tohoto dokumentu, tisících experimentů a terabajtech natrénovaných dat jsem se dostal k finálnímu řešení.
Během projektu jsem:
Finální volba
TFT model s group-features, bez syntetických hodnot, trénovaný na položkách s minimálně 1 měsícem historie.
Výsledek?
Stabilní predikce napříč celým sortimentem, silné zachování sezónnosti a schopnost korigovat chyby v manuálních forecastech zákazníka.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays