V předchozím díle jsem poprvé trénoval model na celém sortimentu – tedy nejen na položkách s plnou 36měsíční historií, ale i na těch, které mají jen několik málo měsíců dat, případně žádnou historii.
Varianta min. 1 měsíc historie přinesla nejvyšší stabilitu – model dokázal využít co nejvíc dat, aniž by se učil na „prázdných“ řádcích. Při detailní validaci se ale ukázalo, že největší slabinou zůstávají položky s méně než 6 měsíci historie.
V pátém díle jsem ukázal, jak dodatečné features promění syrová čísla v „mapu“, ve které se neurální síť zorientuje a předpoví poptávku s užitečnou přesností. Tentokrát ale cílím na položky s krátkou historií, teré v sobě nemají dost informací, aby je model dokázal sám dobře odhadnout.
Co je cílem?
Proč to funguje:
Stejné typy features, které jsem poprvé použil na individuální obrat, jsem teď aplikoval na úrovni skupin:
Pro každou položku navíc počítám poměrové log-features, které dávají modelu jemnější měřítko, o kolik se konkrétní položka liší od své skupiny – což je přesně ten chybějící signál u produktů s krátkou historií.
Opět jsem pro detailnější pohled validaci rozdělil do pěti částí podle délky historie. Validace běžela na modelu trénovaném na položkách s minimálně jedním měsícem historie + přidanými group features.
| Metrika | Celá historie | 36 měsíců | 12-35 měsíců | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 32.4045 | 55.2969 | 30.3056 | 40.9703 | 35.6533 | 41.0825 |
| RMSE | 39.9062 | 20.7024 | 41.4421 | 21.1611 | 25.4482 | 14.6151 |
| R² | 0.8745 | 0.8862 | 0.7558 | |||
| MAPE | 60.6599 | 55.216 | 62.2879 | |||
| ROBUST | 0.5071 | 69.6946 | 0.5078 | 55.8221 | 0.567 | 61.2863 |
| STABLE | 0.3969 | 0.3695 | 0.4645 | |||
| Metrika | 6-12 měsíců | 1-6 měsíců | bez historie | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 43.6437 | 58.8135 | 53.8679 | 59.4594 | 95.8109 | 522.2663 |
| RMSE | 22.9386 | 15.9583 | 48.4724 | 33.3359 | 44.6723 | 27.5461 |
| R² | 0.7551 | 0.647 | -0.0372 | |||
| MAPE | 63.4811 | 73.2619 | 373.445 | |||
| ROBUST | 0.5038 | 64.5602 | 0.5628 | 75.3369 | 0.3612 | 550.8374 |
| STABLE | 0.4537 | 0.4594 | 1.0963 | |||
Krátké a nulové historie jsou pro predikci největší problém – model často netrefí ani základní měřítko (scale). Aby tyto položky dostaly alespoň náznak „minulosti“, nahradil jsem chybějící obrat syntetickými hodnotami. Tyto hodnoty vznikají jako vážený průměr prodejů podobných položek, přičemž:
Další otázku, kterou jsem řešil, kdy syntetiku použít:
| Varianta | Výhody | Nevýhody |
|---|---|---|
| 1️⃣ Syntetika už v tréninku | • Model se hned učí scale novinky → menší sklouzávání k nule. | • Učí se na hodnotách, které nikdy neexistovaly → hrozí šum. |
| • Více „plných“ řad = lepší stabilita | • Připravené vzory mohou přežít i poté, co reálný prodej začne vypadat jinak (přeučení na syntetiku). | |
| • Menší riziko šumu způsobených prázdnými položkami | ||
| 2️⃣ Syntetika až při validaci | • Trénink zůstává „čistý“, bez rizika šumu. | • Model nevidí tyto vzory při učení → může syntetiku ignorovat nebo špatně škálovat. |
| • Snadno otestuju, co syntetika skutečně přináší. | • Možnost zmatení modelu (proč předtím byli nuly a teď ne) | |
| • Kdykoli lze syntetická pravidla vyměnit bez re-tréninku modelu. |
Vyhodnocení jsem znovu rozdělil do pěti částí podle délky historie. Modely již obsahují rozšíření o group-features.
| Metrika | Celá historie | 33 měsíců | 13-32 měsíců | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 32.1862 | 71.2019 | 30.0079 | 43.2471 | 43.5696 | 51.4367 |
| RMSE | 39.8141 | 20.1656 | 41.7923 | 20.6518 | 37.0207 | 18.3537 |
| R² | 0.8751 | 0.8843 | 0.7773 | |||
| MAPE | 71.3488 | 62.8897 | 66.1173 | |||
| ROBUST | 0.5136 | 87.4698 | 0.5182 | 64.0748 | 0.4673 | 65.5932 |
| STABLE | 0.3973 | 0.3686 | 0.544 | |||
| Metrika | 7-12 měsíců | 1-6 měsíců | bez historie | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 66.8159 | 1721.7288 | 52.1569 | 55.7443 | 109.8849 | 788.7963 |
| RMSE | 42.6149 | 22.1131 | 47.9948 | 32.8273 | 43.0087 | 31.3547 |
| R² | 0.4999 | 0.6155 | 0.0386 | |||
| MAPE | 271.8153 | 79.4936 | 605.8361 | |||
| ROBUST | 0.4346 | 1021.1267 | 0.4775 | 86.1018 | 0.4294 | 853.5104 |
| STABLE | 0.804 | 0.6387 | 1.2805 | |||
| Metrika | Celá historie | 33 měsíců | 13-32 měsíců | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 32.48 | 58.1319 | 30.3187 | 40.9103 | 40.6533 | 46.0825 |
| RMSE | 40.0808 | 20.7711 | 39.4421 | 22.8784 | 41.4482 | 19.6151 |
| R² | 0.8734 | 0.8864 | 0.7558 | |||
| MAPE | 61.2626 | 53.188 | 62.8778 | |||
| ROBUST | 0.5068 | 72.6901 | 0.5083 | 52.8141 | 0.5639 | 60.4654 |
| STABLE | 0.3977 | 0.3608 | 0.471 | |||
| Metrika | 7-12 měsíců | 1-6 měsíců | bez historie | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 42.8685 | 58.8836 | 56.0964 | 58.591 | 118.9845 | 885.2588 |
| RMSE | 22.6509 | 15.7021 | 57.7511 | 36.3162 | 44.7058 | 34.277 |
| R² | 0.7587 | 0.6433 | -368.2597 | |||
| MAPE | 63.7576 | 67.9023 | 632.3944 | |||
| ROBUST | 0.5029 | 64.9712 | 0.5526 | 70.3521 | 0.3759 | 937.0026 |
| STABLE | 0.4461 | 0.4816 | 1.3776 | |||
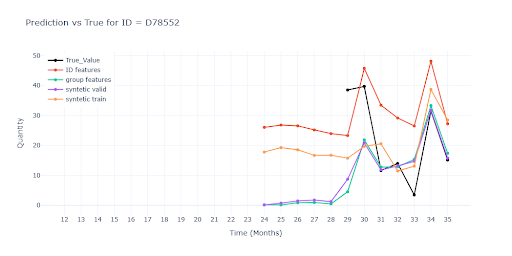
Po čistě číselném srovnání se nabízí otázka, zda má kombinace group-features a syntetických dat vůbec přidanou hodnotu, nebo jde jen o šum v rámci běžné stochastické odchylky? Odpověď na tuto otázku ukáže až vizuální analýza – a právě ta odhalila detaily, které v agregovaných metrikách snadno zaniknou.
Zobrazené modely:
Dlouhá historie prodeje položky



Krátká historie prodeje položky
Bez historie prodeje položky
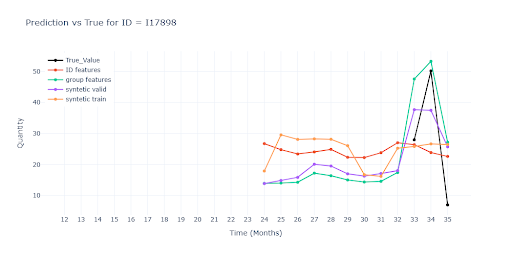
Skupinové features mají největší přínos pro krátké historie, kde dokážou udržet trend i scale blízko realitě. Syntetická data v tréninku naopak často predikci „vyhladí“ a ztratí variabilitu. Bez reálného prodejního bodu ale zůstává predikce nepoužitelná – model nemá z čeho odvodit skutečný obrat.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays