Predikce zásob pomocí AI
7. Feature engineering II - Jak zkrotit sezónu, nuly a promo
Sezónní prodeje
Typickým příkladem jsou vánoční položky. Deset měsíců se neprodávají, v listopadu a prosinci prodej doslova vystřelí. Hlavním úskalím zde bylo naučit model, aby rozpoznal sezónní prodeje od náhodných prodejů nebo outlinerů. V tréninkovém okně (33 měsíců) měla položka takové vrcholy pouze dva, takže model je snadno považoval za šum a dál předpovídal nuly.
Co přesně selhalo
- Málo opakování: dvě špičky ve 33 měsících nevytvoří dostatečný „statistický vzorek“.
- Robustní normalizace: extrémy zjemnila, takže se model „nebál“ je ignorovat.
- Žádný explicitní signál: že daný měsíc je pro položku speciální.
Součástí každé vizualizace je graf znázorňující:
- Černá – Reálný historický prodej
- Červená – Výstup modelu před úpravou
- Zelená – Výstup modelu po úpravě
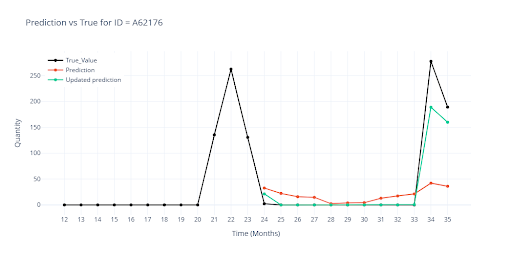
Řešení:
Rozšířil jsem dataset o nové signály, které modelu pomohli pochopit sezónnost:
- Blíží se vrchol: model nyní dostává signál, že právě nastal měsíc (nebo konkrétní časový bod), kdy prodej historicky trvale skáče vysoko – např. Vánoce, Black Friday či letní sezóna.
- Je to sezóna: další signál říká, zda se podobný výstřel zopakoval minimálně ve dvou letech po sobě. Tím model rozliší opakovaný sezónní jev od jednorázového výkyvu.
- Průměrná hodnota vrcholu: spolu s binárními značkami dostává číselnou informaci o průměrném navýšení během vrcholu, takže ví, o kolik kusů typicky navýšit objednávku.
Max. hodnota vrcholu: informace o maximálním dosud zaznamenaném vrcholu.
Nulové predikce
U části sortimentu model tlačil predikce k nule. Položky s velmi nízkým obratem a dlouhými sériemi nul rychle „naučily“ model bezpečné pravidlo → předpovídej stále nulu.
Co přesně selhalo:
- Vyvážení signálu: v datech bylo násobně víc nul než skutečných prodejů, takže model automaticky sklouzl k nulovým predikcím.
- Chyběl kontext „je to normální“: model nepoznal, že občasný prodej je pro danou položku normální rytmus, nikoli šum.
- Normalizace potlačila drobné rozdíly: nízké obraty se ztratily mezi položkami s velkým prodejem.
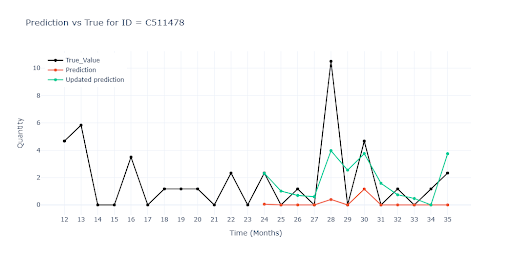
Řešení:
Tento problém byl jedním z nejtěžších. U některých položek – zejména když se spojí nízké objemy a promo akce – se nulové predikce stále tlačily do popředí. Pomohla až změna normalizačního postupu (individuální přístup pro každou feature) a přidání nových kontextových features.
- Stáří položky: model teď ví, jak dlouho už se produkt prodává. Novinky mají na pár nul „právo“, zatímco starší položka s dlouhou pauzou už signalizuje útlum.
- Kdy se naposledy prodalo: kolik měsíců uběhlo od posledního prodeje. Čerstvý prodej ⇒ vyšší pravděpodobnost, že přijde další.
- Jak se dlouho neprodává: kolik měsíců je položka bez prodeje. Čím delší období, tím opatrněji model předvídá nové kusy.
- Sezónní měsíc: připomíná, že v daném měsíci se objevil sezónní prodej.
Slevové akce
Typickým příkladem je drobná elektronika, většinu roku se prodává po jednotkách, ale jakmile e-shop spustí týdenní slevu −20 %, objednávky vyskočí o desítky kusů a po skončení kampaně zase spadnou. V datasetu byli slevové kampaně zastoupeny poměrně často – některé položky je měli i několikrát do roka.
Co přesně selhalo:
- Promo signál se ztratil v davu: po rozšíření datasetu o feature engineering zůstaly jen dvě features přímo spojené s akcí, takže jejich vliv v attention mechanismech modelu výrazně zeslábl. Jinými slovy, v původním datasetu byly promo-indikátory dominantní, nyní se „rozmělnily“ v šumu ostatních vstupů a model je přehlížel.
- Chyběl kontext kampaně: binární příznak SALE sice říkal „teď běží sleva“, ale už neprozradil, jak dlouho trvá ani kdy naposledy se podobná akce objevila.
- Stejná váha pro všechny měsíce: z pohledu ztrátové funkce bylo jedno, zda model podstřelil promo-měsíc, nebo běžný měsíc.
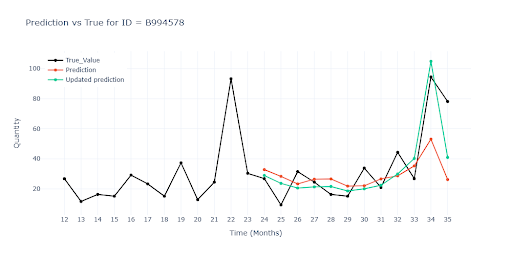
Řešení:
Opět jsem využil feature engineeringu a přidal datasetu nové informace:
- Poslední sleva: model se naučí, že čím delší pauza od poslední akce, tím větší šance, že další sleva obnoví zájem.
- Jak dlouho je sleva: druhý signál říká, jak dlouho už aktuální sleva trvá.
- Aktivita produktu: informace jako je stáří položky, mezery mezi prodeji a kolikrát se položka prodala za poslední rok. Tím se eliminují falešné poplachy u zboží, které se přestalo prodávat.
- Indikátor slevových měsíců: informace, v jakých měsících se v minulosti vyskytovaly slevy.
Jak se změnili metriky
Další test jsem tedy provedl již s těmito úpravami. Na první pohled jsou globální rozdíly malé,u některých metrik se výsledky dokonce mírně zhoršily. Je to logické, položky se sezónním, promo nebo sporadickým prodejem tvoří jen zlomek objemu, takže v souhrnných číslech je „převáží“ zbytek sortimentu. Zhoršení je tedy spíše pravděpodobnostní šum než reálný propad kvality. Vizuální kontrola potvrdila zlepšení modelu u predikce problémových položek.
Je také potřeba mít na paměti, že jde o stochastický problém – model se při každém tréninku trochu liší. Pokud je nastavení správné, tyto odchylky zůstávají malé — typicky v řádu jednotek procent.
| Metrika | Predikce | Nová predikce | ||
|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 28.4178 | 42.0787 | 29.9001 | 39.1834 |
| RMSE | 46.3156 | 21.1877 | 52.8141 | 20.9628 |
| R² | 0.9004 | 0.9072 | ||
| MAPE | 52.4587 | 59.802 | ||
| ROBUST | 0.4986 | 59.7858 | 0.5259 | 62.4322 |
| STABLE | 0.3677 | 0.3702 | ||