V minulém díle padlo rozhodnutí opřít další vývoj o deep-learningové architektury. Aby byly budoucí vizualizace lépe čitelné, budu dál soustředit pozornost především na Temporal Fusion Transformer (TFT). K této volbě mě přivedly tři zásadní argumenty:
Na začátku se sice zdálo, že model DeepAR dosahuje srovnatelných metrik při nižších výpočetních nárocích, ale jakmile jsme rozšířili vstupy o složitější sezónní, promo a relativní signály, rozdíl se otočil: výkon TFT začal škálovat, zatímco DeepAR narážel na své limity.
V průběhu dalšího testování se velmi rychle ukázala nevýhoda prvního scénáře – tedy kdy tréninkové a validační data byli shodné.
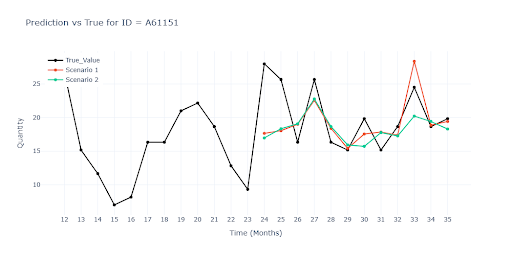
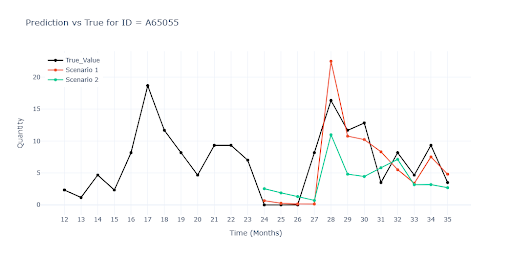
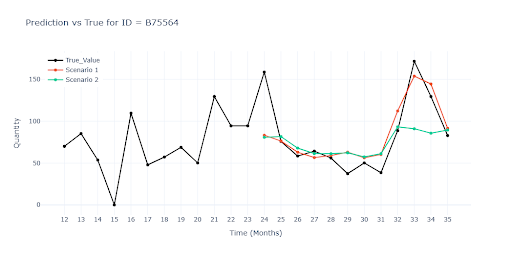

V grafech lze vidět, že Scénáři 1 sleduje predikce pro realitu velmi dobře po celou dobu, protože model měl možnost „budoucnost“ vidět. Jakmile dostal zcela nové 3 měsíce (Scénář 2), rozdíl se projevil velmi rychle. Na posledním grafe se sezónním zboží lze vidět, že model totálně selhával.
| Metrika | Scenario 1 | Scenario 2 | ||
|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 32.1632 | 45.7959 | 53.1177 | 66.9848 |
| RMSE | 62.0655 | 25.2746 | 83.1493 | 45.7434 |
| R² | 0.8603 | 0.7754 | ||
| MAPE | 63.9494 | 95.889 | ||
| ROBUST | 0.4796 | 66.0129 | 0.4184 | 98.0722 |
| STABLE | 0.3819 | 0.4615 | ||
Při kontrole výsledků scénáře 2 je vidět, že model vykazuje určitou schopnost predikce, zejména u položek s dlouhou a stabilní historií. Výsledky ale byly stále výrazně pod očekáváním. Ukázalo se, že model zásadně selhává ve třech klíčových oblastech:
Bylo zřejmé, že model potřebuje další vstupy, z nichž vyčte kontext, který v surových číslech chybí – feature engineering.
Při práci s AI nad časovými řadami má každý řádek v datech podobu:
Produkt × Časový okamžik (např. položka A v březnu 2024).
Vše ostatní na řádku – jako je segment, druh, obrat, cena nazýváme features. Tyto sloupce dávají modelu potřebné souvislosti – pomáhají pochopit chování produktu v čase, jeho podobnost s ostatními a vliv okolních faktorů jako jsou promo akce nebo sezóna.
Proč?
Jak bylo řečeno, v našem datasetu tvoří každý řádek dvojici Produkt (ID) × Měsíc (time_idx).
Vše ostatní nazýváme features.
Seznam features pro dataset projektu
ID, seasonality, category, type, segment, segment 1, segment 2, name, turnover, date, time_idx, weight, SALE, SALE_INTENSITY, product_volume__bin
3 typy features
Základní rozdělení je na statické a dynamické, tedy jestli se hodnoty mění v čase.
Typ zboží je pro všechny měsíce stejný, naopak slevová akce je pouze v několika měsících.
| Typ feature | Příklad | Jak pomáhá modelu |
|---|---|---|
| Statické | Typ, ID, kategorie, segment | Síť sdílí vzory napříč sortimentem a pomáhá novinkám, které mají málo historie. Hodnoty jsou stejné pro všechny měsíce. |
| Dynamické známé | Kalendář, sleva | Hodnoty se mění v každém měsíci, známe je i pro budoucí měsíce. |
| Dynamické neznámé | obrat | Hodnoty se mění v každém měsíci, neznáme je pro budoucí měsíce. Jedná se většinou o veličiny, které chceme předpovědět. |
Číselné vs. kategorické
Proč embeddings fungují
Dva vektory uložené „blízko sebe“ = dvě kategorie, jejichž poptávka se chová podobně. Nový produkt z „nářadí“ tak okamžitě těží z historie „elektro-příslušenství“, pokud je jejich prodejní profil příbuzný.
V této fázi tréninku jsem se zaměřil na features, které pomáhají modelu pochopit vztah mezi obratem v jednotlivých měsících. Každá skupina těchto vstupů doplňuje jiný typ informace: sezónní rytmus, vývoj v čase, vliv promoakcí i relativní chování vůči ostatním položkám.
🗓️ Date-encoding
Model nepracuje s měsíci, ale s číselným pořadím (time_idx je 0 – 36). Pomocí těchto features mu tyto vazby identifikujeme.
📊 Relativní (poměrové) features
🌀 Lag & Rolling okna
🌊 Wavelet signály
📈 Trend
🔢 Absolutní i log-hodnoty
Většinu features jsem vytvořil jak v absolutních hodnotách, tak i v logaritmické hodnotě.
Proč logaritmus?
Pomocí této kombinaci vstupů model nejen předpovídá obrat, ale chápe i kontext jednotlivých měsíců: co je běžný trend, co je výkyv, a co znamená promo.
Po sérii iterací jsem skončil na cca 75 featurách — tato sada přinesla největší zlepšení metrik vůči nárokům na čas a paměť. Další navyšování features už výsledek zlepšovalo jen minimálně, zatímco trénink výrazně zpomalovalo. Kombinace více features pak také vedla ke vzájemnému ovlivňování.
Grafy porovnávají odezvu tří verzí modelu:
Kontrast mezi křivkami ukazuje, jak každý balík features zlepšuje (nebo mění) schopnost modelu sledovat reálný prodej.

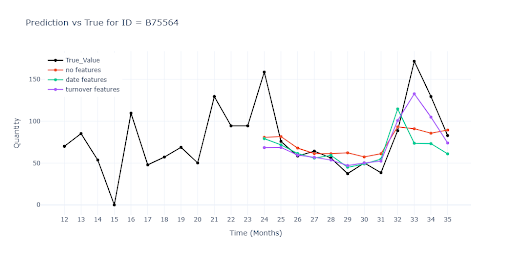
Metriky ukazují, jak přidané informace posunují kvalitu modelu:
| Metrika | bez features | datumové features | obratové features | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 53.1177 | 66.9848 | 32.0651 | 46.7711 | 30.2608 | 44.5829 |
| RMSE | 83.1493 | 45.7434 | 72.175 | 25.1354 | 46.1427 | 22.3537 |
| R² | 0.7754 | 0.8111 | 0.9012 | |||
| MAPE | 95.889 | 62.9665 | 60.0505 | |||
| ROBUST | 0.4184 | 98.0722 | 0.4907 | 65.2697 | 0.4948 | 62.2027 |
| STABLE | 0.4615 | 0.3839 | 0.365 | |||
Na testovacím vzorku jsem změřil, jak rostoucí počet featur zatěžuje zdroje (13 featur = základ).
| Features | Čas tréninku | GPU memory |
|---|---|---|
| 120 | x 7 | x 2,5 |
| 444 | x 26 | x 6 |
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays