Vstupní data jsem od zákazníka obdržel ve formátu textových výstupů – tedy jako CSV soubory. Integraci přímo do firemních systémů jsem v této fázi záměrně neřešili; cílem bylo ověřit funkčnost AI modelu nad daty.
Každý řádek v souborech představoval jeden produkt v daném období a obsahoval informace:
Celkově šlo přibližně o 15 000 různých položek. Základním časovým indexem byl měsíc, což umožňuje sledovat vývoj prodejů i skladových zásob v čase.
Už při prvním pohledu bylo jasné, že data nejsou kompletní a obsahují celou řadu nesrovnalostí:
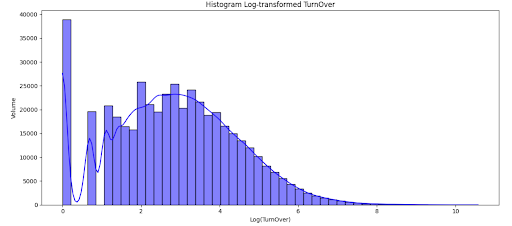
První graf (boxplot) ukazuje rozložení obratů produktů napříč celým datasetem (logaritmicky transformovaných), druhý graf (histogram) ukazuje četnost jednotlivých obratů.
Medián log(obratu) je přibližně 3,5, což odpovídá typickému obratu kolem 33 kusů za měsíc. Většina produktů má hodnotu v intervalu 2,2 – 4,2 (tedy zhruba 9 až 67 kusů za měsíc), ale v datech najdeme i několik položek s výrazně vyššími obraty – outlinery od 7.3 (1480 kusů).

Je vidět, že velké množství produktů má nulový nebo velmi nízký obrat (vlevo), zatímco nejvyšší hustota prodejů je mezi hodnotami log(obratu) 2–4, což odpovídá rozmezí 7 až 55 jednotek měsíčně. Na pravé straně histogramu se nachází pouze malá skupina produktů s opravdu vysokým obratem – jedná se o výjimky, které ale významně ovlivňují celkový objem prodejů.
Než bylo možné začít s trénováním predikčního modelu, bylo nezbytné data důkladně připravit a vyčistit. Právě tato fáze je v AI projektech často časově nejnáročnější a významně ovlivňuje kvalitu výsledků.
Data byla následně převedena do tzv. „long“ formátu, kde každý řádek představuje jednu kombinaci zboží a měsíce. Výsledný dataset zahrnoval cca 15 000 položek zboží a přes půl milionu řádků.
Seznam sloupců ve výsledném datasetu
Na seznamu níže je vidět struktura připraveného datasetu ve formátu „long“.
Dataset obsahuje nejen základní identifikátory a obchodní informace, ale i několik doplňujících a speciálně vytvořených sloupců, které jsou klíčové pro správné fungování modelu (-weight-, –time_idx-).
ID, seasonality, category, type, segment, unit, name, turnover, price, ordered, date, time_idx, weight, SALE, SALE_INTENSITY
Hlavním cílem projektu byla predikce skladových zásob. Po detailní analýze dat a zhodnocení reálných možností se však ukázalo jako nejvhodnější predikovat nejprve obrat (tedy předpokládaný prodej) každého zboží. Na základě těchto predikcí pak bude možné pomocí běžných logistických postupů a pravidel (např. min/max sklad, dodací lhůty, pojistné zásoby) dopočítat optimální množství zásob pro každý měsíc.
Po hlubší analýze jsem dospěl k rozhodnutí, že některé sloupce nebudou použity pro trénink modelů, protože nemají přímý vliv na obrat zboží:
| Segment | počet položek | průměrná hodnota | směrodatná odchylka | rozptyl |
|---|---|---|---|---|
| AA-BB-UU | 91 | 20.925 | 44.316 | 2 001.933 |
| AA-EE-DD | 89 | 54.869 | 70.83 | 5 114.107 |
| AA-GG-LL | 88 | 26.011 | 33.747 | 1 160.926 |
| AA-AA-SS | 89 | 84.013 | 173.254 | 30 598.405 |
| XX-WW-TT | 91 | 50.484 | 89.99 | 8 255.076 |
| GG-PP-AA | 86 | 28.943 | 40.32 | 1 657.201 |
| DD-GG-VV | 85 | 4.494 | 5.227 | 27.855 |
| HH-EE-RR | 81 | 12.802 | 11.232 | 128.596 |
| AA-DD-OO | 79 | 21.321 | 36.809 | 1 381.121 |
| BB-WW-TT | 77 | 90.052 | 141.141 | 20 306.666 |
| Segment2 | počet položek | průměrná hodnota | směrodatná odchylka | rozptyl |
|---|---|---|---|---|
| DD | 2645 | 32.412 | 169.623 | 29 329.194 |
| FF | 2689 | 119.556 | 455.99 | 211 954.269 |
| GG | 1687 | 32.537 | 67.237 | 4 608.307 |
| AA | 1288 | 63.001 | 150.065 | 22 955.733 |
| BB | 611 | 104.113 | 287.801 | 84 433.946 |
| HH | 509 | 84.453 | 249.227 | 63 317.309 |
| KK | 512 | 49.896 | 230.821 | 54 310.314 |
| OO | 471 | 39.45 | 102.916 | 10 796.918 |
| PP | 436 | 56.652 | 159.096 | 25 801.689 |
| 339 | 30.97 | 84.214 | 7 229.437 |
Následující tabulky ukazují zastoupení skupin v segmentech (prvních 10 položek).
Pro každou skupinu je uveden počet unikátních produktů (number ID), průměrný obrat (mean_target), směrodatná odchylka (std_target) a variance obratu (var_target).
Tyto přehledy ukazují, že v každé úrovni segmentace existují podskupiny s výrazně odlišnými objemy a rozptylem prodejů, což znamená, že přesná segmentace a analýza skupin umožňuje modelu lépe odhadnout poptávku i tam, kde je historie krátká nebo výkyvy velké. Podobnou analýzu jsem provedl také pro ostatní skupiny, jako je sezónnost, kategorie a typ zboží.
ID, seasonality, category, type, segment, segment1, segment2, unit, name, turnover, date, time_idx, weight, SALE, SALE_INTENSITY, product_volume_bin
Data jsou vyčištěná, dataset připravený. V této fázi vše vypadalo bez větších komplikací. Dalším logickým krokem bylo otestovat výstupy referenčních modelů – tedy klasických machine learning algoritmů, jako jsou lineární regrese a rozhodovací stromy.
Právě zde ale přišla první skutečná výzva: Jak vlastně data správně vyhodnocovat, když tradiční metriky přestávají fungovat?
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays