Predikce zásob pomocí AI
2. Struktura dat a první analýza
První pohled na data
Vstupní data jsem od zákazníka obdržel ve formátu textových výstupů – tedy jako CSV soubory. Integraci přímo do firemních systémů jsem v této fázi záměrně neřešili; cílem bylo ověřit funkčnost AI modelu nad daty.
Každý řádek v souborech představoval jeden produkt v daném období a obsahoval informace:
- Unikátní identifikátor produktu (stejný ve všech souborech)
- Sezónnost, kategorii, druh a segment zboží
- Popis rozdělení na subkategorie
- Měrnou jednotku a podrobný popis zboží
- Historii za posledních 36 měsíců
- Obrat (v jednotkách i v měně)
- Množství objednaného zboží
- Termíny a označení promo akcí
Celkově šlo přibližně o 15 000 různých položek. Základním časovým indexem byl měsíc, což umožňuje sledovat vývoj prodejů i skladových zásob v čase.
Už při prvním pohledu bylo jasné, že data nejsou kompletní a obsahují celou řadu nesrovnalostí:
- Chybějící historie prodejů: U mnoha produktů zcela chyběla část nebo celá historie, typicky se to týkalo nových či výrazně sezónních položek.
- Záporné prodeje: některé záznamy vykazovaly záporné hodnoty prodejů, často šlo o vratky, storna nebo chyby v zadání.
- Nesoulad v jednotkách: Různé typy jednotek významně ovlivňují interpretaci obratů a prodejů (například kusy vs. gramy, jednotky vs. tisíce)
- Duplicitní záznamy: některé položky se objevily opakovaně se stejnými nebo lehce odlišnými parametry.
- Trvání promo akcí: Promo akce byly v datech zaznamenány v počtu dnů, zatímco prodeje byly evidovány měsíčně.
- Různá délka historie: Zatímco některé produkty měly tříletou historii, u části zboží byla k dispozici jen data za několik měsíců.
- Chybějící data: Chybějící datumy, kategorie, apod.
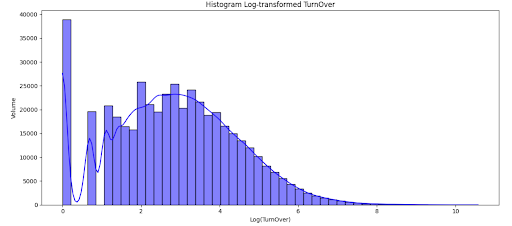
První graf (boxplot) ukazuje rozložení obratů produktů napříč celým datasetem (logaritmicky transformovaných), druhý graf (histogram) ukazuje četnost jednotlivých obratů.
Medián log(obratu) je přibližně 3,5, což odpovídá typickému obratu kolem 33 kusů za měsíc. Většina produktů má hodnotu v intervalu 2,2 – 4,2 (tedy zhruba 9 až 67 kusů za měsíc), ale v datech najdeme i několik položek s výrazně vyššími obraty – outlinery od 7.3 (1480 kusů).

Je vidět, že velké množství produktů má nulový nebo velmi nízký obrat (vlevo), zatímco nejvyšší hustota prodejů je mezi hodnotami log(obratu) 2–4, což odpovídá rozmezí 7 až 55 jednotek měsíčně. Na pravé straně histogramu se nachází pouze malá skupina produktů s opravdu vysokým obratem – jedná se o výjimky, které ale významně ovlivňují celkový objem prodejů.
Import dat a čištění
Než bylo možné začít s trénováním predikčního modelu, bylo nezbytné data důkladně připravit a vyčistit. Právě tato fáze je v AI projektech často časově nejnáročnější a významně ovlivňuje kvalitu výsledků.
- Chybějící historie prodejů
Jedním z hlavních problémů byla neúplná historie prodejů.
V některých případech skladový systém exportoval nulu jako prázdnou hodnotu, jindy zboží v daném měsíci vůbec neexistovalo, a proto byl obrat také prázdný.
Aby model správně rozlišil, kdy je nulový obrat skutečně nulou (zboží existovalo, ale neprodalo se), a kdy jde o položku, která v daném měsíci na skladě ještě nebyla, vytvořil jsem nový sloupec –weight – označující existenci zboží v daném období.
- Záporné prodeje
V datech od zákazníka se objevily záporné hodnoty prodejů – tyto situace byly způsobeny vratkami zboží. Po dohodě byly tyto hodnoty převedeny na nulu, aby model nebyl těmito anomáliemi ovlivněn.
- Nesoulad v jednotkách
Další výzvou byl nesoulad v měrných jednotkách – model musí umět pracovat s jednotkami přesně tak, jak je eviduje zákazník. Sjednocení jednotek napříč sortimentem nebylo možné, proto bylo klíčové naučit model škálovat a správně interpretovat hodnoty i v případě rozdílných objemů (jednotky vs tisíce).
- Trvání promo akcí
Kromě základních údajů obsahovala data i informace o promo akcích v konkrétních dnech. Zatímco obraty byly evidovány měsíčně, promo akce byli ve dnech a přesahovaly mezi měsíci. Proto byl vytvořen nový sloupec, který popisuje procentuální platnost proma v každém měsíci – promo trvalo 50% měsíce.
- Různá délka historie
Některé produkty měly pouze krátkou historii, protože vznikly až v průběhu analyzovaného období. Pro zachování konzistence dat bylo třeba, aby všechny položky měly stejně dlouhou časovou osu – i zde byl využit sloupec weight pro existenci zboží, který pomohl správně označit období, kdy položka ještě neexistovala. - Duplicitní záznamy a chybějící data
Ve spolupráci se zákazníkem byla data dále dočištěna – byly odstraněny duplicity i další chybějící hodnoty tak, aby co nejméně negativně ovlivňovaly trénování modelu.
Výsledná struktura
Data byla následně převedena do tzv. „long“ formátu, kde každý řádek představuje jednu kombinaci zboží a měsíce. Výsledný dataset zahrnoval cca 15 000 položek zboží a přes půl milionu řádků.
Seznam sloupců ve výsledném datasetu
Na seznamu níže je vidět struktura připraveného datasetu ve formátu „long“.
Dataset obsahuje nejen základní identifikátory a obchodní informace, ale i několik doplňujících a speciálně vytvořených sloupců, které jsou klíčové pro správné fungování modelu (-weight-, –time_idx-).
ID, seasonality, category, type, segment, unit, name, turnover, price, ordered, date, time_idx, weight, SALE, SALE_INTENSITY
První analýzy a objevené vzory
Hlavním cílem projektu byla predikce skladových zásob. Po detailní analýze dat a zhodnocení reálných možností se však ukázalo jako nejvhodnější predikovat nejprve obrat (tedy předpokládaný prodej) každého zboží. Na základě těchto predikcí pak bude možné pomocí běžných logistických postupů a pravidel (např. min/max sklad, dodací lhůty, pojistné zásoby) dopočítat optimální množství zásob pro každý měsíc.
Klíčová rozhodnutí při analýze dat
Po hlubší analýze jsem dospěl k rozhodnutí, že některé sloupce nebudou použity pro trénink modelů, protože nemají přímý vliv na obrat zboží:
- Cena: Prodejní cena v daných podmínkách neměla přímý vliv na objem prodejů.
- Objednáno: Kvalita dodavatelů a doba dodání ovlivňuje zásoby, ale nikoliv samotný obrat – tyto proměnné se tedy využijí až ve druhém kroku, při dopočtu optimálních zásob.
- Položka Segment: Tato proměnná popisovala tříúrovňové rozdělení zboží do různých segmentů. Pro co nejkomplexnější informaci jsem do datasetu zahrnul všechny úrovně segmentace, tedy „Segment“, „Segment 1“ a „Segment 2“.
| Segment | počet položek | průměrná hodnota | směrodatná odchylka | rozptyl |
|---|---|---|---|---|
| AA-BB-UU | 91 | 20.925 | 44.316 | 2 001.933 |
| AA-EE-DD | 89 | 54.869 | 70.83 | 5 114.107 |
| AA-GG-LL | 88 | 26.011 | 33.747 | 1 160.926 |
| AA-AA-SS | 89 | 84.013 | 173.254 | 30 598.405 |
| XX-WW-TT | 91 | 50.484 | 89.99 | 8 255.076 |
| GG-PP-AA | 86 | 28.943 | 40.32 | 1 657.201 |
| DD-GG-VV | 85 | 4.494 | 5.227 | 27.855 |
| HH-EE-RR | 81 | 12.802 | 11.232 | 128.596 |
| AA-DD-OO | 79 | 21.321 | 36.809 | 1 381.121 |
| BB-WW-TT | 77 | 90.052 | 141.141 | 20 306.666 |
| Segment2 | počet položek | průměrná hodnota | směrodatná odchylka | rozptyl |
|---|---|---|---|---|
| DD | 2645 | 32.412 | 169.623 | 29 329.194 |
| FF | 2689 | 119.556 | 455.99 | 211 954.269 |
| GG | 1687 | 32.537 | 67.237 | 4 608.307 |
| AA | 1288 | 63.001 | 150.065 | 22 955.733 |
| BB | 611 | 104.113 | 287.801 | 84 433.946 |
| HH | 509 | 84.453 | 249.227 | 63 317.309 |
| KK | 512 | 49.896 | 230.821 | 54 310.314 |
| OO | 471 | 39.45 | 102.916 | 10 796.918 |
| PP | 436 | 56.652 | 159.096 | 25 801.689 |
| 339 | 30.97 | 84.214 | 7 229.437 |
Následující tabulky ukazují zastoupení skupin v segmentech (prvních 10 položek).
Pro každou skupinu je uveden počet unikátních produktů (number ID), průměrný obrat (mean_target), směrodatná odchylka (std_target) a variance obratu (var_target).
Tyto přehledy ukazují, že v každé úrovni segmentace existují podskupiny s výrazně odlišnými objemy a rozptylem prodejů, což znamená, že přesná segmentace a analýza skupin umožňuje modelu lépe odhadnout poptávku i tam, kde je historie krátká nebo výkyvy velké. Podobnou analýzu jsem provedl také pro ostatní skupiny, jako je sezónnost, kategorie a typ zboží.
- Nesoulad v jednotkách: Jednou z výhod deep learning přístupu je, že model umí využít informace nejen z historie konkrétního zboží, ale z celého sortimentu – tedy porovnávat i položky, které spolu na první pohled nesouvisí. V praxi to ale přináší výzvu ve škálování obratů: například když jedna položka vykazuje obrat ve stovkách kusů, jiná ve stejné skupině jen jednotky a další dokonce tisíce.
- Aby model správně pracoval s tak rozdílnými hodnotami a nedocházelo ke zkreslení výsledků, vytvořil jsem speciální sloupec product_volume_bin, který obsahuje informaci o velikosti běžného obratu produktu. Díky této kategorizaci může model lépe rozlišovat položky s různými objemy prodejů a přesněji pracovat s jejich vzájemnými vztahy napříč celým sortimentem.
- Výsledná struktura datasetu
ID, seasonality, category, type, segment, segment1, segment2, unit, name, turnover, date, time_idx, weight, SALE, SALE_INTENSITY, product_volume_bin
Závěr a navazující kroky
Data jsou vyčištěná, dataset připravený. V této fázi vše vypadalo bez větších komplikací. Dalším logickým krokem bylo otestovat výstupy referenčních modelů – tedy klasických machine learning algoritmů, jako jsou lineární regrese a rozhodovací stromy.
Právě zde ale přišla první skutečná výzva: Jak vlastně data správně vyhodnocovat, když tradiční metriky přestávají fungovat?