Predikce zásob pomocí AI
1. Zadání & úvod do projektu
„Správné plánování zásob je problém, který řeší nejen velké firmy, ale i menší a střední podniky napříč obory. A právě jim dnes AI otevírá úplně nové možnosti.“
Po třech letech intenzivního studia AI jsem se rozhodl pustit do vlastního projektu: aplikace Deep Learningu pro predikci skladových zásob.
Proč právě toto téma? Oslovil mě známý s otázkou, zda by umělá inteligence mohla vyřešit problém s plánováním skladových zásob ve velkoobchodu.
Ukázalo se, že správa zásob je nikdy nekončící úkol – je těžké najít rovnováhu mezi přezásobením a rizikem, že zboží dojde v ten nejméně vhodný okamžik. Navíc vstupuje do hry řada proměnných, které se v čase mění.
Jak číst tuto sérii
Cílem této série je přiblížit svět predikce skladových zásob lidem z businessu – tedy těm, kteří skutečně řeší každodenní provoz a plánování zásob, a zároveň chtějí vědět, jak jim může AI a moderní data pomoci v praxi. Nebudu se zde pouštět do technických detailů, budu se soustředit na konkrétní situace a problémy, které tato problematika obnáší.
Vždy představím reálný problém, ukážu jsem ho řešil, a vše doložím na konkrétním příkladu nebo grafu – aby si každý mohl udělat jasnou představu, co AI v logistice (ne)umí a proč.
Mým cílem je, aby si v sérii našli své jak manažeři, kteří chtějí vědět, jak AI může pomoci v byznysu, tak i analytici, kteří se chtějí dozvědět, jak konkrétní rozhodnutí a zpracování dat ovlivňuje výsledky predikcí v praxi.
Veškerá data vycházejí z reálných projektů, jsou ale anonymizovaná. Série bude vycházet postupně, jak budu mít nové poznatky a zajímavé příklady z praxe.
Popis problému
- Nízké desítky tisíc různých SKU
- Rozdělení podle sezónnosti, kategorie, druhu i segmentu
- Každý měsíc vznikají i zanikají desítky položek
- Slevové akce
- Skladové zásoby se predikují ručně, v kompetenci nákupčích
Definice cíle
Najít mechanismus, který bude:
- Sledovat aktuální skladové zásoby
- Predikovat budoucí prodeje
- Zohledňovat další parametry: dodací lhůty (lead time), spolehlivost dodávek, promo akce, apod.
- Doporučovat kolik zboží objednat a nastavovat min/max zásoby automatizovaně
Prodejní obraty pro různé produkty (SKU): Každá linie představuje vývoj prodejů konkrétního produktu v období 24 měsíců. Je dobře vidět, že jednotlivé položky se liší jak objemem prodejů, tak sezonními výkyvy a obdobími bez prodeje. Tyto rozdíly v chování produktů ilustrují, proč je predikce skladových zásob tak náročná – a proč vyžaduje mnohem sofistikovanější přístup než jednoduchý průměr či extrapolace minulých výsledků.
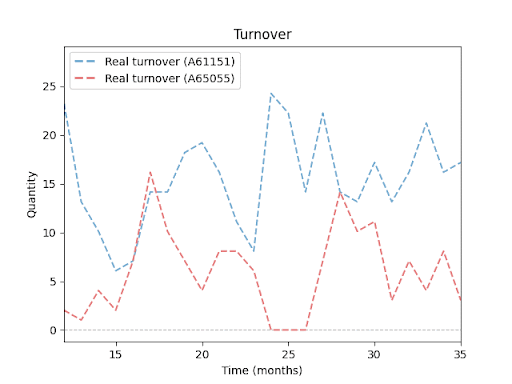
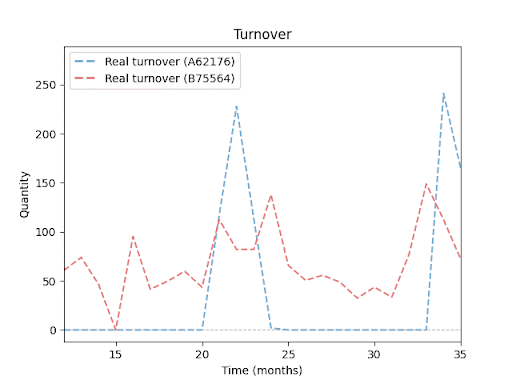
Zadání projektu
Abychom tento cíl mohli naplnit, bylo nutné jasně stanovit, jaké konkrétní požadavky, omezení a rizika bude projekt zahrnovat.
- Automaticky nastaví každý měsíc doporučené min/max zásoby pro každou položku
- Bude zohledňovat parametry:
- Produktové rozdělení
- Akční prodeje
- Sezónnost
- Historie prodejů
- Podobnosti mezi zbožím
- Nové položky
- Finančně dostupné řešení
- Možnost si model otestovat model na vlastních datech
Rizika projektu
Od začátku bylo jasné, že model bude čelit celé řadě výzev:
- Jednorázové extrémy v prodejích
(např. nečekané hromadné objednávky)
- Proměnlivost sortimentu
(každý rok zanikají i vznikají desítky položek, sortiment se vyvíjí
- Různá délka historie položek
(novinky a zboží s dlouhou historií)
- Nulové obraty
(dlouhá období bez prodejů, nárazové obnovení poptávky)
- Velké rozdíly v objemech prodejů
(od kusových položek po tisícové objemy)
- Velké rozdíly v objemech prodejů
- Závislost mezi produkty
(prodej jednoho produktu ovlivňuje poptávku po jiném
- Vliv sezónnosti a plánovaných akcí
Cílem projektu tedy nebylo pouze vytvořit model, který dokáže předpovědět běžnou poptávku, ale především takový, který si poradí i s těmito specifickými a často velmi obtížně předvídatelnými situacemi.
Tabulka historie zboží
ukazuje, jak různorodá byla délka dostupné historie u jednotlivých produktů. Zatímco většina produktů měla kompletní tříletou historii, významná část sortimentu měla jen omezená nebo žádná historická data – což představovalo zásadní problém pro tradiční predikční modely.
| Délka historie produktu | Počet položek | Podíl na sortimentu |
|---|---|---|
| 36 měsíců (plná historie) | 10 105 | 70.00% |
| 12–35 měsíců | 2 668 | 18.00% |
| méně než 12 měsíců | 1 211 | 8.00% |
| bez historie | 519 | 4.00% |
Řešení – ve zkratce
Mnoho firem si myslí, že stačí nakrmit AI daty a výsledek přijde sám. Jak ukázal tento projekt, realita je daleko složitější. První testy ukázaly, že ani moderní deep learning modely (bez úprav) nestačí – narážely na velkou variabilitu sortimentu, množství nulových prodejů a časté změny v sortimentu.
Projekt se proto postupně rozšiřoval – bylo třeba:
- Vylepšit přípravu dat (feature engineering)
- Naučit modely pracovat s extrémy
- Řešit různé délky historie
- Dynamicky škálovat vstupy
Dnes model zvládá většinu komplikací automaticky a bez nutnosti ručních zásahů.
Výsledek
| Metrika | Hodnota | Význam pro byznys |
|---|---|---|
| Přesnost predikce | 80% | Jak dobře model odhadl budoucí prodeje |
| Prům. odchylka | 48 | Průměrná rozdílnost mezi predikcí a realitou |
| Prům velikost chyby | 31 | Průměrná „velikost chyby“ v počtech prodaných kusů |
Hlavní přednosti řešení
- Predikce s přesností přes 80 % napříč sortimentem
- Model vychází z individuální historie i skupinového chování podobných produktů
- Zvláštní důraz jna akční/promo položky
- Predikce i pro nově zavedené položky s minimální historií
- Schopnost reagovat na sezónnost i krátkodobé trendy
- Automatizované výstupy pro celý sortiment
Možnost škálování a opakovaného využití
Řešení lze přizpůsobit dalším zákazníkům, většina algoritmů a klíčových funkcí je předdefinovaná a znovupoužitelná. Stále je sice potřeba odborná znalost při úvodní konfiguraci a interpretaci výsledků, ale samotné nasazení a validace modelu jsou výrazně rychlejší než při vývoji na míru.
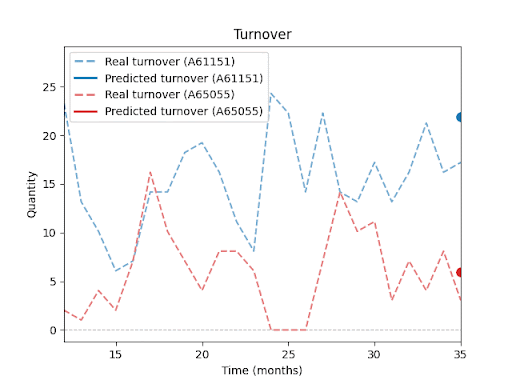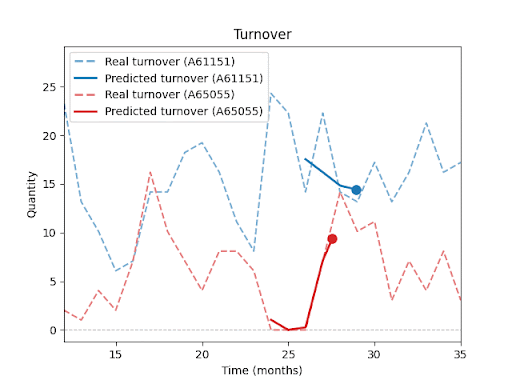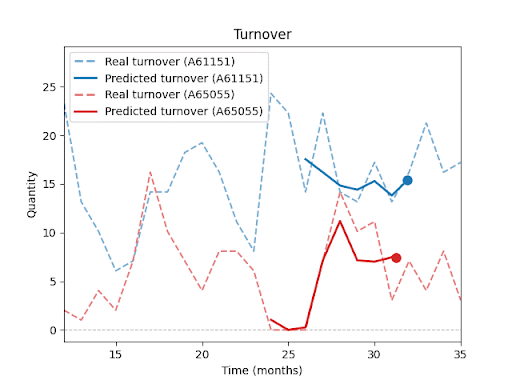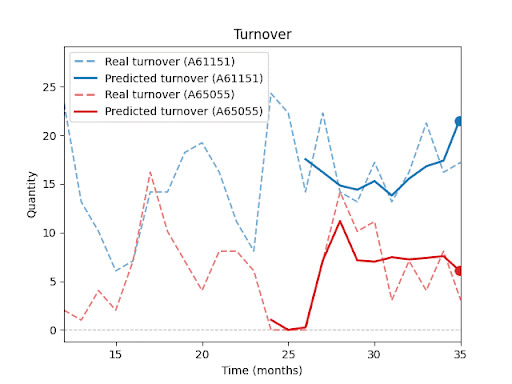
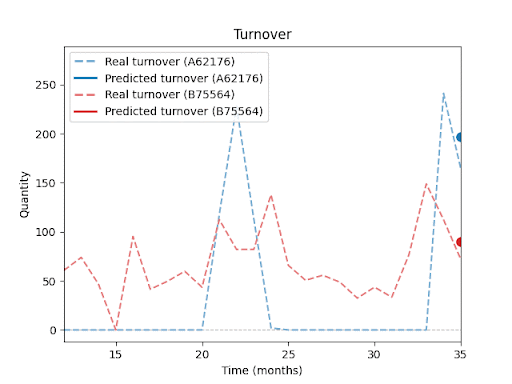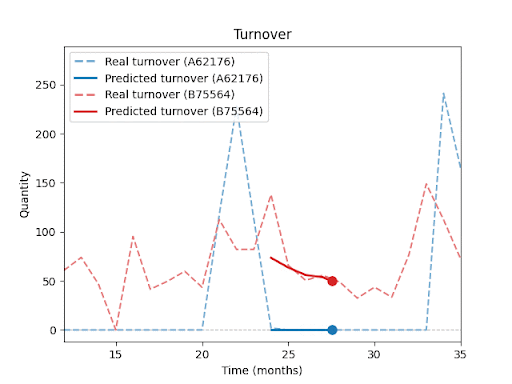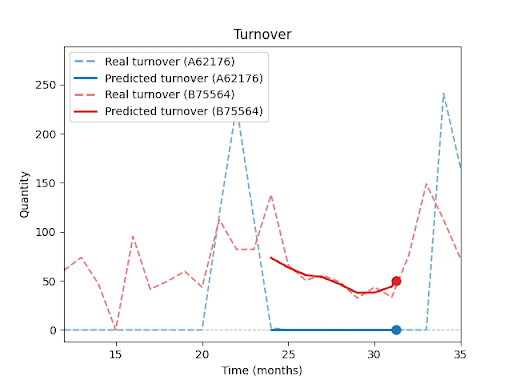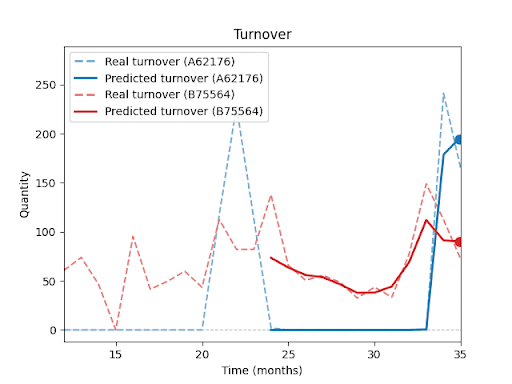
Jak predikci ovlivňuje délka historie, ostatní položky v sortimentu, sezónnost nebo promo akce, se budu podrobněji věnovat v dalších dílech této série.
Technologické zázemí projektu
Celý projekt jsem postavil na frameworku PyTorch, který patří mezi nejpoužívanější open-source platformy pro deep learning. Trénování probíhalo na GPU kartě NVIDIA RTX 3090 s 24 GB paměti, což umožnilo efektivně zpracovávat i velmi rozsáhlá data a testovat různé scénáře, včetně modelů se stovkami milionů parametrů, a to bez výrazných časových prodlev.
Infrastruktura běžela na Kubernetes, díky čemuž je řešení snadno škálovatelné i přenosné – lze jej spustit jak u zákazníka „on-premise“, tak v cloudu, podle aktuálních potřeb a požadavků.