V předchozích článcích jsem se zaměřil na business pohled – kdy dávají smysl statistické modely, machine learning a deep learning. Tento článek jde o vrstvu níž. Zaměřuje se na to, jak je řešení skutečně postavené, jaká rozhodnutí je potřeba udělat a proč samotný model tvoří jen malou část celého problému.
Cílem není popis teorie, ale ukázat, jak experimenty v praxi vznikají a jak jsou vyhodnocované.
Statistické, machine learning a deep learning modely nebyly testované jako oddělené přístupy. Všechny pracovaly nad stejným datasetem a shodnou přípravou dat. Klíčový rozdíl tak nebyl v datech samotných, ale v množství a složitosti technických rozhodnutí, která bylo potřeba udělat, aby jednotlivé přístupy fungovaly.
Každý experiment definuji jako kombinaci nezávislých rozhodnutí, která lze samostatně měnit a vyhodnocovat. Typicky jde o:
Každou z těchto částí lze upravovat nezávisle a sledovat její dopad na výsledky. Cílem není najít jedno optimální nastavení, ale pochopit, jak jednotlivé části ovlivňují chování modelu.
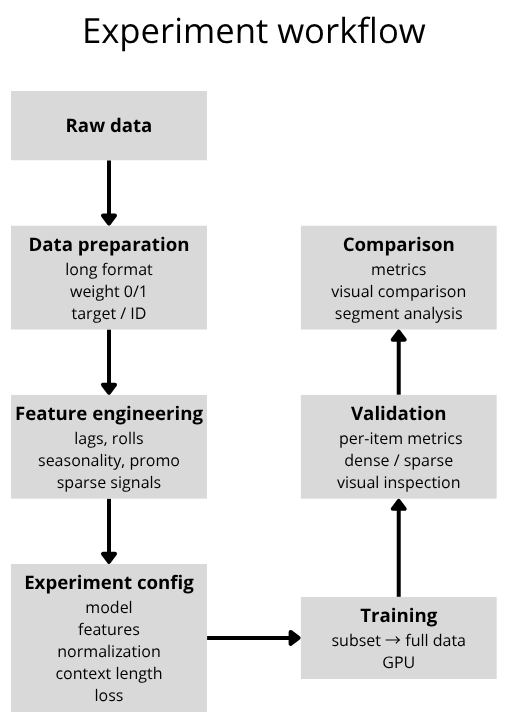
Dataset je připravený ve formátu long, kde každý řádek reprezentuje kombinaci časového kroku a konkrétního ID. Důležitou součástí je binární feature `weight`, která označuje, zda položka v daném čase skutečně existovala. Tato informace je klíčová, protože většina frameworků neumí pracovat s chybějícími hodnotami (NaN). Bez explicitního rozlišení by model považoval neexistující historii za reálná data.
Feature engineering převádí raw data na signál, který se model dokáže naučit. Správně navržené features umožňují modelu zachytit vztahy, které nejsou z raw dat přímo viditelné. U komplexních nebo nepravidelných dat má tato vrstva často větší dopad než samotná volba modelu.
Zahrnuje zejména:
Každý experiment je plně definovaný konfigurací. Mezi jednotlivými variantami neměním kód, ale pouze parametry. Díky tomu lze systematicky testovat různé kombinace a přímo je mezi sebou porovnávat.
Každou z těchto částí mohu měnit nezávisle a sledovat její dopad na výsledky. Experiment je popsaný konfigurací, která určuje jak zpracování dat, tak samotný model:
"Experiment TFT 1": {
"config_def": {
"TARGET_NORMALIZER" : {"method":"standard", "group":True, "center":True, "transformation":"none"},
"FEATURE_NORMALIZER": {"method":"default", "group":True, "center":None},
"LOSS_WEIGHT": {"zero":0.8, "low":1, "normal":1, "high":1},
},
"params": {
"model_name": "TFT",
"epochs": 40,
"batch_size": 256,
"optimizer": "AdamW",
"learning_rate": 1e-3,
"learning_strategy": "plateau",
"dropout" : 0.1,
"hidden_size" : 128,
"layers" : 2,
"prediction_length": prediction_length,
"encoder_length": encoder_length,
"loss": "QuantileLoss([0.1, 0.3, 0.5, 0.85, 0.95])",
"gradient_clip_val" : 0.5,
"hidden_continuous_size": 8,
},
"features": list_of_features,
},
list_of_features= [
("bins_volume",{}),
("sell_time_features",{}),
("encode_date_harmonics", {"harmonics": [1, 2, 3]}),
("discount_action_features",{}),
("peak_seasons",{"is_peak":False}),
("lag_feature",{"lags":["1M", "1Y", 6]}),
("roll_log_feature",{"rolls":["1M", "1Y", "2Y"]}),
("trend_Group_feature",{}),
("lag_Group_feature",{}),
("wavelet_target_group",{}),
]
Frameworky nepracují s chybějícími hodnotami (NaN), proto je nutné explicitně definovat, co představuje reálnou historii a co pouze kontext. Proto používám binární feature `weight`:
Model tak vidí kompletní časovou strukturu, ale není penalizován za části, které neodpovídají reálné historii. To je zásadní zejména u položek s krátkou historií, kde velká část časové osy neobsahuje skutečná data.
Syntetický kontext používám pro rozšíření krátkých časových řad na délku encoderu. Je generovaný na základě podobnosti položek – využívám statické atributy, například skupinu zboží. Model se tak neučí pouze z omezené historie jedné položky, ale využívá vzory napříč podobnými položkami. Stejný princip platí i pro embeddings, kde nové nebo sparse položky nejsou zpracovávané izolovaně, ale v kontextu celé skupiny.
Experimenty neprobíhají jako jednorázové trénování modelu, ale jako iterativní proces. Začínám na menším vzorku dat (stovky až tisíce ID), kde rychle testuji základní kombinace parametrů. Jakmile se objeví funkční nastavení, postupně ho rozšiřuji na celý dataset.
Díky konfiguraci není potřeba měnit kód – upravuji pouze parametry a systematicky porovnávám výsledky napříč různými variantami. Celý proces je omezený výpočetním výkonem (GPU), proto běží experimenty postupně a každá varianta využívá maximální dostupný výkon.
Výsledky vyhodnocuji kombinací automatizované analýzy a ruční kontroly (pomocí Weights & Biases). Nezaměřuji se pouze na globální metriky, ale sleduji výsledky i na specifických typech položek a pomocí vizuální analýzy predikcí.
Validace probíhá nad časovými kroky, které nebyly použity při tréninku, aby odpovídala reálnému scénáři predikce. Metriky nepočítám globálně přes celý dataset. Nejprve je počítám pro každou položku zvlášť a až následně je agreguji.
Tento přístup mi umožňuje:
Vedle průměrných metrik sleduji také konkrétní časové řady (sezónní, sparse, nepravidelné), protože samotná metrika často neukáže typ chyby.

U stabilnějších projektů hodnotím především chybu množství:
Dále používám upravené varianty WAPE pro lepší interpretaci:
U projektů se sparse daty, kde vysoký výskyt nul výrazně ovlivňuje metriky používám jiný přístup, kdy identifikuji dvě části problému:
Používám proto metriky rozdělené podle typu situace:
Cílem není optimalizovat jednu metriku, ale pochopit chování modelu v různých situacích.
Výsledkem je sada vyhodnocených experimentů, s popsanou konfigurací, kterou lze jednoduše upravovat bez zásahu do implementace. Jednotlivé části – vstupy, reprezentace dat, normalizace, loss nebo model – měním nezávisle a sleduji jejich dopad na výsledky. Celá série projektů ukázala, že kvalita predikce není určena jedním modelem, jednou metrikou ani jedním „správným“ přístupem. Rozhodující je především charakter samotných dat.
Stabilní datasety s dostatečně dlouhou historií lze často velmi dobře řešit pomocí relativně jednoduchých přístupů. Jakmile ale data začnou kombinovat krátkou historii, nepravidelnost, sparse chování, sezónnost, promo akce nebo externí vlivy, problém se výrazně komplikuje — a rozdíly mezi jednotlivými přístupy začínají být zásadní.
Experimenty zároveň ukázaly, že hlavní deep learning výhoda spočívá ve schopnosti pracovat se složitostí:
Jedním ze závěrů celé série je také to, že agregované metriky samy o sobě nestačí. Modely s podobnými průměrnými výsledky se mohou výrazně lišit v chování na kritických produktech nebo při důležitých výkyvech. Vyhodnocení predikce proto vyžaduje nejen numerické metriky, ale i kontextovou a vizuální analýzu.
Série zároveň ukázala jednu praktickou realitu, která se v diskusích o AI predikcích často podceňuje: největší problém obvykle není natrénovat model, ale vytvořit proces, který umožní experimenty systematicky řídit, porovnávat a převádět do reálného rozhodování.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays