Předpovídání poptávky a řízení skladových zásob patří mezi oblasti, kde je realita velmi komplexní. V praxi se kombinuje několik nepravidelných vlivů:
A právě proto se dnes čím dál častěji používá AI a moderní metody predikce. Nejde o „sci-fi“, ale o nástroje, které umí v datech vidět vztahy, které člověk už prostě není schopen držet v hlavě. Tradiční přístupy jako klouzavé průměry nebo jednoduché statistické modely fungují dobře tam, kde je poptávka stabilní. U složitějších kategorií ale rychle narazí.
Modernější modely strojového učení nebo hlubokého učení dokážou pracovat s více zdroji dat najednou, pochopí sezónnost i nepravidelnosti a často dokážou odhalit vzorce, které by ručně v praxi nikdo nesložil.
Cílem tohoto textu je ukázat tři hlavní směry, kterými lze předikci zásob řešit:
a vysvětlit, kde dává smysl zůstat u jednoduchých nástrojů a kde se naopak vyplatí sáhnout po něčem komplexnějším.

V praxi existují tři hlavní cesty, jak řešit predikci poptávky (pokud vynecháme LLM, která jsou spíš na textové úlohy, ne na časové řady). Tyto přístupy nejsou konkurenti, ale různé nástroje pro různé typy problémů.
Statistické metody patří mezi nejjednodušší. Pracují s předpokladem, že budoucnost se bude chovat podobně jako minulost.
Kde fungují dobře:
Výhody:
Nevýhody:
Tyto modely hledají vztahy mezi mnoha vstupy a výstupy, nesnaží se popsat sérii jednou rovnicí.
Kde fungují dobře:
Výhody:
Nevýhody:
Deep Learning modely umí samy pochopit, jak se série chová v čase. Využívají vzorce, které si samostatně naučí z dat.
Kde fungují nejlépe:
Výhody:
Nevýhody:
V reálném světě málokdy existuje „ideální“ produktová řada. Častěji se setkáváme s mixem:
A to celé navíc zhoršují kategorie, které se chovají jinak, změny cen, chyby v datech, lokální rozdíly a lidský faktor. Jedním z nejčastějších problémů v praxi je špatná volba vstupů. Buď se modelu některé důležité informace nedají (protože se berou automaticky), nebo se naopak použije příliš nepodstatných dat. Cílem modelu není vysvětlit příčinu chování, ale dostat jasný a relevantní vstup, který odpovídá reálnému signálu.
Dopad: nepřesnosti, nadzásoby, nebo vyprodané položky.
Dopad: méně výpadků, menší zásoby, lepší práce s promo efekty.
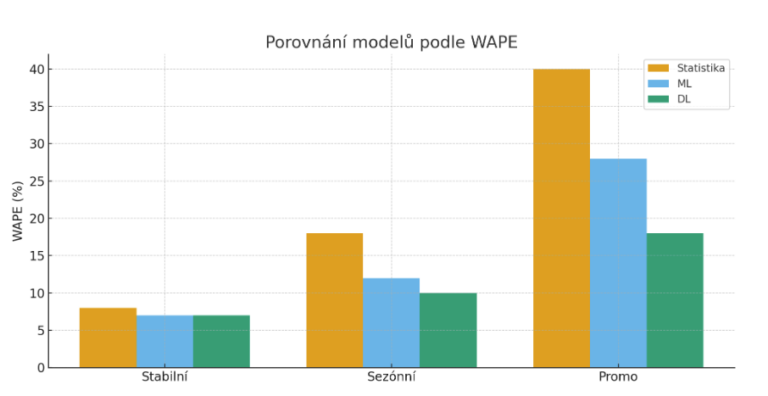
Dopad: u nejkomplexnějších produktů může přesnost stoupnout o 20–40 % oproti ML.
DL modely jsou nejsilnější, ale neznamená to automaticky, že jsou vždy správná volba. Při výběru je nutné zvážit:
Někdy se investice do složitějšího modelu vyplatí okamžitě, jindy přinese jen minimální zlepšení oproti ML nebo statistice. Nejvíce užitku mají tam, kde opravdu záleží na přesnosti: zboží s výkyvy, promo efekty, krátkou trvanlivostí nebo vyšší hodnotou.
Co získám přechodem na složitější model:
| Typ sortimentu | Zlepšení přesnosti | Dopad na zásoby | Dopad na vyprodanost |
|---|---|---|---|
| Stabilní | 1–3 % | minimální | žádný |
| Sezónní | 8–12 % | snížení zásob 3–5 % | méně výpadků v sezóně |
| Promo / nestabilní | 20–40 % | snížení zásob 10–20 % | méně výpadků, vyšší tržby |
DL modely často vypadají jako něco, co si mohou dovolit jen velké firmy s vlastním datovým oddělením. Realita se ale za poslední roky změnila. Knihovny, frameworky a nástroje dokážou obrovskou část práce udělat automaticky. Není potřeba mít tříčlenný tým datových vědců a rok vývoje. Stačí pár dobrých rozhodnutí na začátku.
Nejčastější chyba je skočit rovnou do nejkomplexnějších modelů. Správnější je začít u jednoduchých:
Baseline je kontrolní bod, bez kterého nevíte, jestli vám dražší řešení skutečně pomůže.
Pokročilé modely dnes není nutné vyvíjet ručně. Frameworky umožňují snadno:
Ne všechny položky potřebují pokročilé modely. Najděte skupinu „problematičtějších“ produktů, kde současné predikce často selhávají:
Stačí začít u malé podskupiny, kde jsou chyby predikcí nejdražší.
Není realistické očekávat, že každá firma bude ladit architektury modelů, featury a parametry. Smysluplnější přístup je:
Můžete se pak soustředit pouze na to, co je podstatné: jestli model zlepšuje rozhodování a snižuje náklady.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays