Forecasting demand and managing inventory belong to areas where real-world behavior is highly complex. In practice, several irregular influences interact at the same time:
This is exactly why AI and modern forecasting methods are increasingly used today. They are not “sci-fi”, but tools capable of identifying patterns in data that people can’t realistically hold in their heads. Traditional approaches like moving averages or basic statistical models work well where demand is stable, but they quickly hit their limits in more complex categories.
Modern machine learning and deep learning models can work with multiple data sources simultaneously, capture seasonality and irregularities, and often uncover patterns that would be impossible to assemble manually.
The aim of this article is to outline three main families of forecasting approaches:
and explain where simple tools are sufficient and where it makes sense to use more sophisticated techniques.

In practice there are three main directions for demand forecasting (leaving aside LLMs, which are designed for text rather than time series). These approaches are not competitors, but different tools for different types of problems.
These are among the simplest methods. They assume that the future will behave similarly to the past.
Where they work well:
Advantages:
Limitations:
These models search for relationships between many inputs and outputs, without trying to describe the series with one equation.
Where they work well:
Advantages:
Limitations:
Deep learning models can learn how a time series behaves directly from data. They identify patterns automatically.
Where they work best:
Advantages:
Limitations:
In the real world, an “ideal” product assortment almost never exists. Instead, we typically see a mix of:
And all of that is further complicated by category differences, price changes, data errors, local specifics and human decisions. One of the most common issues is poor selection of inputs. Models often receive too little (because some factors are taken for granted and never passed in), or too much (irrelevant variables introducing noise). The goal of a model is not to explain causality — it needs clear and relevant signals.
Impact: inaccuracies, overstocks or stockouts.
Impact: fewer stockouts, lower inventory, better handling of promo effects.
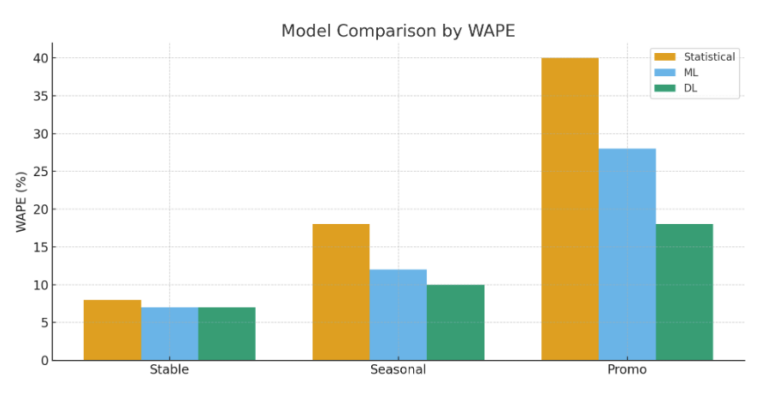
Impact: for highly complex products, accuracy may improve by 20–40% compared to ML.
DL models are the most powerful, but that doesn’t mean they’re always the right choice. It is important to evaluate:
Sometimes the investment into a complex model pays off immediately; sometimes the improvement over ML or statistics is minimal. DL models shine where accuracy has high business value: volatile products, promo-driven categories, short shelf-life or high-value items.
| Product Type | Improvement | Inventory Impact | Stockout Impact |
|---|---|---|---|
| Stable | 1–3 % | Minimal | None |
| Seasonal | 8–12 % | inventory reduction 3–5 % | Fewer stockouts |
| Promo / Irregular | 20–40 % | inventory reduction 10–20 % | Fewer stockouts, higher revenue |
DL models often look like something only large companies with dedicated data teams can handle. Fortunately, the landscape has changed. Libraries, frameworks and automated tools take over most of the heavy lifting. You don’t need a three-person data science team and a year of development.
Don’t jump straight into the most complex model. A better path:
A baseline is your reference point. Without it, you cannot tell if a more complex approach is worth it.
Modern frameworks allow you to:
The principle is simple: test first, adjust later.
Not every item needs a DL model. Start with categories where prediction errors hurt the most:
A small targeted use case can reveal most of the value.
It is unrealistic to expect every company to tune architectures, features and hyperparameters. A more practical approach is:
This allows you to focus on what matters: whether the model improves decision-making and reduces costs.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays