Predikce zásob pomocí AI
4. Referenční modely vs DeepLearning
Proč začít u klasických ML modelů
- Rychlý reality-check – Základní algoritmy se trénují v řádu minut a okamžitě odhalí, zda v datech není zásadní problém (chybný kalendář, duplikované řádky apod.).
- Referenční laťka – Jakmile známe výkon lineární regrese či rozhodovacího stromu, můžeme přesně vyčíslit, o kolik se musí zlepšit deep-learning, aby jeho nasazení dávalo ekonomický smysl.
- Transparentnost – Jednodušší modely se lépe vysvětlují; pomáhají porozumět vztahu mezi vstupy a výstupy ještě před nasazením komplexnější architektury.
| Referenční modely | Jak fungují |
|---|---|
| LR – Linear Regression | Umí zachytit jednoduchý rostoucí / klesající trend. Jakmile jsou data složitější, rychle ztrácí přesnost. |
| DT – Decision Tree | Umí složitější křivky a nelinearity, ale pokud strom nechám růst moc hluboko, začne být přetrénovaný - opakuje se. |
| FR – Random Forest | Zprůměruje chyby jednotlivých stromů → stabilnější než jeden strom, ovšem náročnější na paměť a pomalejší při velkém počtu položek. |
| XGB – XGBoost Regressor | Často nejlepší z klasických ML – umí zachytit složité vztahy i bez složitého ručního ladění. |
| GBR – Gradient Boosting Regressor | Hodí se jako levné srovnání: když selže i on, data jsou opravdu náročná. |
Jak vypadá vizualizace 4 položek, predikce na 12 měsíců?
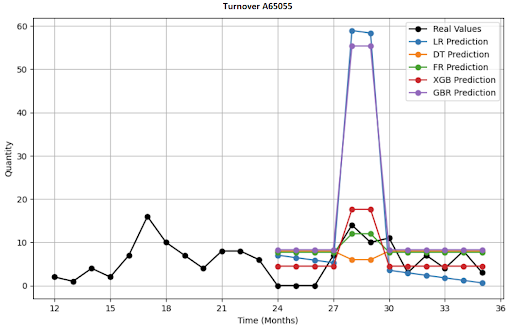
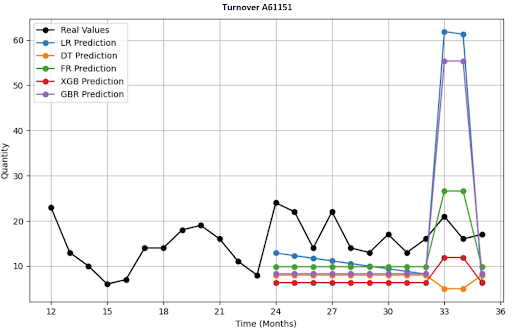
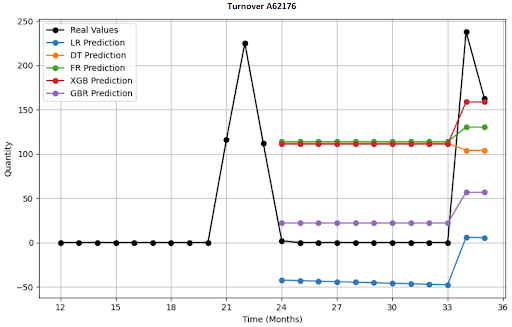
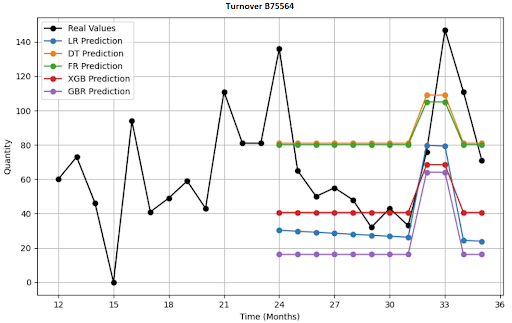
Deep-learningové architektury, které jsem nasadil?
Pro porovnání jsem vytvořil 3 základní DL modely. Ve všech případech se jedná o AI modely pro časové řady, jestliže referenční modely patřili k tomu jednoduššímu, tak tyto patří k tomu komplexnějšímu.
| DL algoritmus | Jak funguje | Výhody/nevýhody |
|---|---|---|
| DeepAR (autoregresivní LSTM) | Učí se z podobných položek, při predikci generuje celé pravděpodobnostní rozmezí poptávky ⇒ vidíme optimistický i pesimistický scénář prodejů | Novinky, long-tail, při spoustě nul a extrémů má tendenci křivku „vyhlazovat“. |
| TFT (Temporal Fusion Transformer) | Výborný na komplexní scénáře, sám si vybere, která informace je důležitá, umí výběr vysvětlit. | Komplexní datové sady s mnoha externími signály, potřebuje hodně dat, trénink je časově náročný. |
| N-HiTS (Hierarchical Interpolation) | Rozloží sérii na víc časových hladin (roky / měsíce / týdny), na každé vrství vlastní malou síť — nakonec je složí zpět. | Dlouhé predikční horizonty a potřeba rychlých výpočtů, vyžaduje pravidelný časový krok. |
Proč tyto komlexní modely?
- Vytěží jemné i dlouhé sezónní vzorce a promo efekty, které klasická ML přehlédne.
- Sdílejí znalost napříč sortimentem — pomáhají novinkám i položkám s krátkou historií.
- Vracejí interval nejistoty, takže nákupčí dostává doporučení „kolik objednat v optimistickém a pesimistickém scénáři“.
Jak vypadá vizualizace 4 položek, predikce na 12 měsíců u DL modelů?

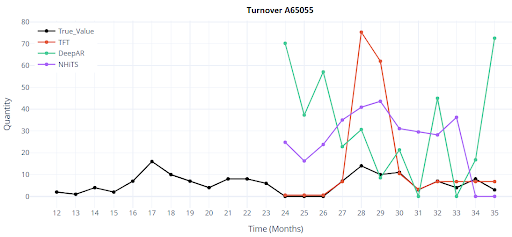
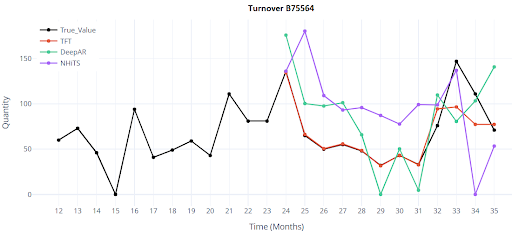
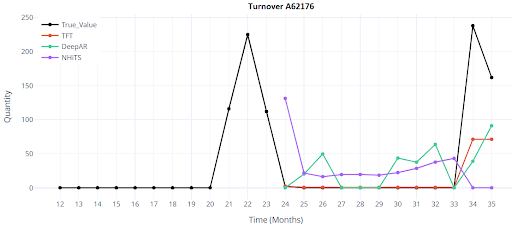
Výsledky
Testování jsem prováděl pouze při scénáři 1, tedy validace i trénink probíhala na stejném datasetu. Použil jsem 5000 položek zboží, pouze s plnou historií 36 měsíců.
Klasické modely dávají prvotní orientaci, ale ani ty nejlepší z nich se nepřibližují cílové přesnosti. Deep-learning přináší skokové zlepšení — už v základní konfiguraci snižuje chybu na polovinu či třetinu. To je rozhodující signál, že má smysl investovat čas do ladění featur, hyper-parametrů a produkčního nasazení.
Metriky porovnávající ML a DL modely. Pokročilé metriky pro validaci jsem začal používat až později.
| ML - referenční modely | ||||
|---|---|---|---|---|
| Metrika | R² | WAPE | RMSE | MAPE |
| GBR | 0.4259 | 124.9833 | 173.599 | 275.8702 |
| FR | 0.3444 | 133.5684 | 157.6839 | 217.063 |
| DT | 0.2529 | 142.5767 | 165.8517 | 212.5132 |
| XGB | 0.2153 | 146.125 | 168.5045 | 266.1286 |
| LR | 0.0745 | 158.6966 | 200.3072 | 477.9817 |
| DeepLearning modely | ||||
|---|---|---|---|---|
| Metrika | R² | WAPE | RMSE | MAPE |
| DeepAR | 0.847 | 53.615 | 62.8242 | 188.5804 |
| TFT | 0.3901 | 30.2255 | 125.4162 | 141.6336 |
| NHiTS | 0.432 | 206.9327 | 121.0321 | 382.6455 |
Test číslo 2 - Encoder vs Decoder
V předchozí fázi jsem si ověřil, že hlubší (DL) architektury skutečně výrazně převyšují klasické ML. Než jsem se pustil do ladění parametrů typu loss, optimizer nebo drop-out (které zde nebudu rozebírat), je nutné dobře porozumět architektuře encoder–decoder, která v modelech pro časové řady je klíčovou komponentou a určuje, kolik minulosti model „čte“ a jak dlouho do budoucna predikuje.
Encoder: Říká, jak dlouhý úsek minulosti model použije pro vytvoření jedné konkrétní předpovědi. Analogie nákupčího, který se dívá např. na posledních 12 měsíců historie.
Decoder: Pohled do budoucnosti – na základě informací od encoderu vygeneruje predikce.
Architektura ale na rozdíl od nákupčího vytvoří při tréninku několik predikcí (klouzavá okna) pro každé zboží. Mám-li 36 měsíců historie, chci aby se model koukal na posledních 18 měsíců a predikoval 3 měsíce, pak při tréninku se vytvoří 18 klouzavých oken nad těmito měsíci:
| Encoder | Decoder |
|---|---|
| 0-18 | 19-21 |
| 1-19 | 20-22 |
| ... | ... |
| 17-35 | 36-38 |
Tříletá historie tak vytváří 18 tréninkových scénářů pro každou položku; model vidí všechny možné přechody (zima → jaro, vánoce → leden apod.).
Hlavní rozdíl a vliv na chování modelu:
Jaký je rozdíl při nastavení délky encoderu 18 a 30 měsíců? Klíčový rozdíl je v tom, jaké typy vzorců se model naučí a na co bude klást důraz. Je to klasický kompromis mezi flexibilitou a stabilitou.
| Encoder_length = 18 | Encoder_length = 30 |
|---|---|
| Lepší adaptace na změny: Model rychleji zareaguje, na náhlé změny na trhu (trend, promo) | Dobrý v dlouhodobé sezónnosti: Lépe rozpozná opakující se vzorce a pomalé dlouhodobé trendy. |
| Více tréninkových oken: Rychlejší učení, menší riziko přetrénování u položek s krátkou historií. | Stabilnější predikce: Robustnější k výkyvům v posledních měsících |
| Nižší paměťové a časové nároky: rychlejší inference. | Méně tréninkových oken: Delší trénink, vyšší riziko přetrénování, pokud dat není dost. |
| Hůře vidí sezónní cykly: Model nemusí plně pochopit vzorce, které se opakují ve víceletých cyklech. | Pomalejší reakce na změny: trvá déle se adaptovat na náhlé změny na trhu (trendy, proma) |
| Sezónní paměť: Větší riziko, že vánoční špičku z minulosti úplně „zapomene“. | Vyšší paměťové a časové nároky |
Jak tedy vybrat?
Neexistuje univerzálně nejlepší volba. V praxi jsem testoval 12 / 18 / 24 / 30 měsíců a jako nejvyváženější se ukázal encoder = 18 měsíců, decoder = 3 měsíce. Ten nabízí dost historie, přitom generuje velký počet tréninkových oken a dobře reaguje na krátkodobé změny trhu.