V předchozím článku jsem pracoval s datasetem, kde hlavní výzvou byla sezónnost a promo akce. Tyto vlivy měly negativní dopad na jednodušší modely a naopak zvýraznily výhodu komplexnějších přístupů, které dokázaly lépe zachytit změny v čase.
Druhý projekt řeší zásadně odlišný typ problému. Na rozdíl od prvního projektu zde problém nespočívá v nedostatku historie, ale v tom, že většina dat neobsahuje žádnou informaci. Model zde neřeší jen velikost prodeje, ale především to, zda k prodeji vůbec dojde. To má přímý dopad na plánování – chyba zde neznamená jen nepřesnost, ale buď zbytečně držené zásoby, nebo naopak nedostupné zboží.
Predikce se tím přirozeně rozpadá na dvě části:
Tento rozdíl zásadně mění chování modelů i způsob, jakým je potřeba hodnotit jejich kvalitu.
Dataset obsahuje týdenní prodeje pro přibližně 5 000 produktů za období 3 let.
Rozdíly jsou patrné i v objemech:
Základní charakteristika datasetu je shrnutá v následující tabulce:
| Parametr | Hodnota |
|---|---|
| Počet produktů | 5 000 |
| Frekvence dat | týdenní |
| Nejdelší historie | 161 týdnů |
| Nejkratší historie | 2 týdny |
| Podíl období 1 - 6 měsíců | 1.7% |
| Podíl období 7 - 12 měsíců | 2.3% |
| Podíl období 13 - 24 měsíců | 13.1% |
| Podíl období 24+ měsíců | 92.8% |
| Průměrná velikost prodeje | 38.2 |
| Průměrná velikost prodeje (bez nulových hodnot) | 89.4 |
| Medián prodeje (bez nulových hodnot) | 5.0 |
| Maximální prodej | 63 400 |
| Podíl nulových prodejů | 57.3% |
Z pohledu plánování jde o méně typický, ale velmi důležitý scénář – zejména pro sortiment s nízkou obrátkou. Pro lepší srovnání jsou výsledky v grafech uváděny v měsících, i přes týdenní frekvenci datasetu.
Stejně jako v předchozím projektu probíhaly testy na podmnožinách datasetu rozdělených podle délky historie jednotlivých produktů.
Důvod je jednoduchý – délka historie zásadně ovlivňuje kvalitu predikce.
Každý z těchto scénářů představuje jiný problém – a právě jejich kombinace s vysokým podílem nulových prodejů výrazně ovlivňuje chování jednotlivých modelů.
Pro porovnání jednotlivých přístupů byla použita stejná validační strategie jako v předchozím projektu. Modely byly trénovány na historických datech a testovány na následujícím období. Tento přístup odpovídá reálnému použití, kdy predikujeme budoucnost na základě minulosti.
U tohoto datasetu je ale potřeba hodnotit dvě věci současně:
Metrika proto kombinuje oba pohledy – penalizuje jak chybný odhad množství, tak nesprávnou predikci nulových prodejů. Výsledná hodnota reprezentuje celkovou velikost chyby – čím nižší číslo, tím přesnější predikce. Důležité je ale vnímat ji v kontextu jednotlivých scénářů, protože rozdíly mezi modely se zde projevují jinak než v předchozím projektu.
Analýzou datasetu jsem identifikoval, že hlavním problémem je vysoký podíl nulových prodejů.
Aby bylo možné grafy správně interpretovat, je dobré se zaměřit na několik klíčových aspektů:
Právě kombinace těchto faktorů určuje, jak složitá je predikce daného produktu. Podívejme se nyní na konkrétní příklady, jak tato data skutečně vypadají v praxi.
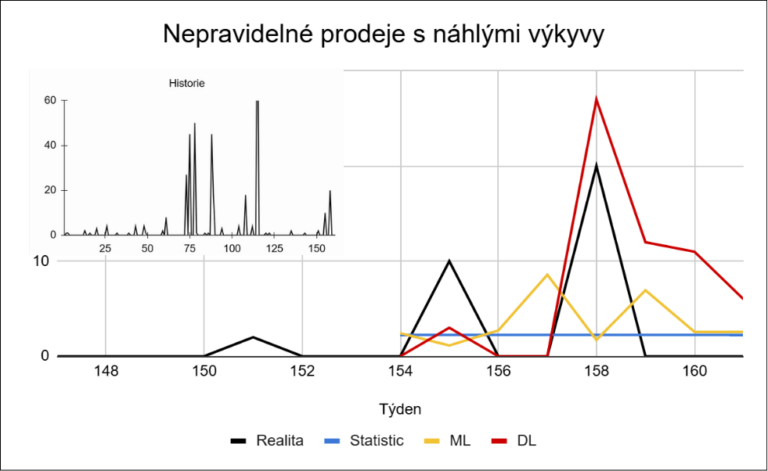
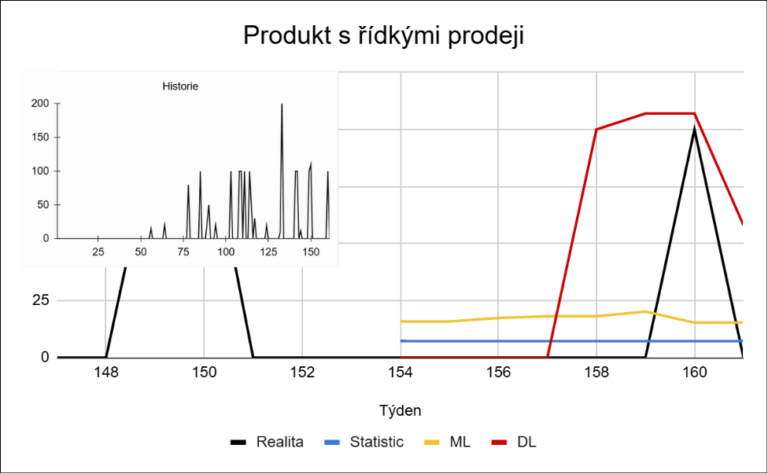
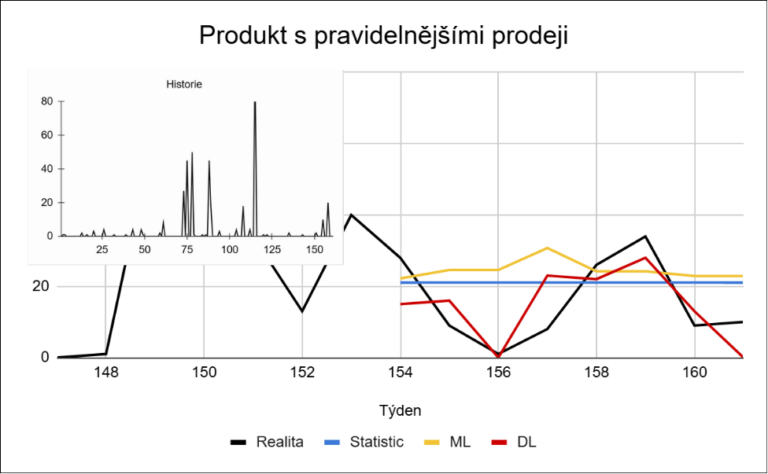
Tyto příklady ukazují, že problém sparse dat není pouze ve vysokém podílu nulových prodejů. Jednotlivé produkty se liší nejen v tom, jak často se prodávají, ale i v tom, jak velké jsou jejich prodeje a jak stabilní je jejich chování v čase. U sparse dat přitom nejde jen o velikost chyby, ale o to, zda model dokáže správně odhadnout samotný výskyt prodeje.
Tyto rozdíly se následně promítají i do výsledků modelů. Podívejme se, jak si jednotlivé přístupy vedly napříč scénáři.
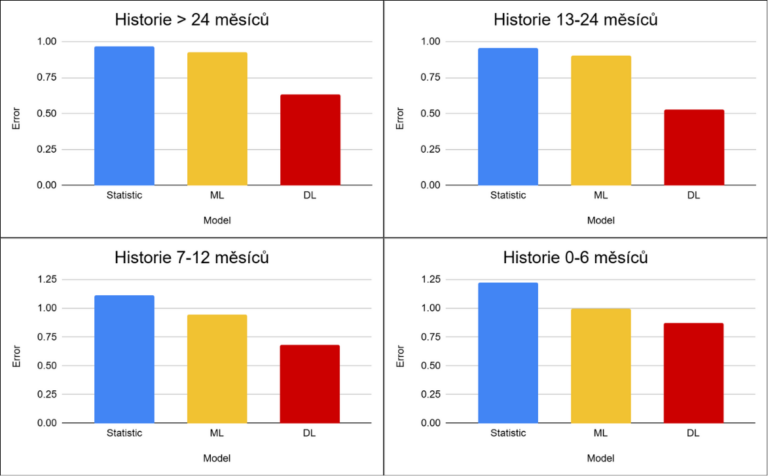
Po pochopení charakteru dat se můžeme podívat na to, jak si jednotlivé přístupy vedly v praxi. Stejně jako v předchozím projektu byly výsledky vyhodnoceny podle délky historie produktů. Na rozdíl od prvního projektu jsou v tomto případě rozdíly mezi přístupy výrazné napříč všemi scénáři. Deep learning dosahuje ve všech případech nejlepších výsledků, a to s poměrně stabilním odstupem od ostatních přístupů. V průměru snižuje chybu o více než 50% oproti statistickým metodám a o 40 % oproti machine learningu.
Důvodem je charakter datasetu. Vysoký podíl nulových prodejů a nepravidelné chování produktů vytváří prostředí, ve kterém jednodušší modely nedokážou efektivně zachytit strukturu dat. Statistické metody i Machine learning mají tendenci zjednodušovat realitu – často se přibližují průměru nebo vytváří stabilní predikce, které ale neodpovídají skutečnému chování dat. Deep learning si v tomto scénáři vede lépe zejména díky schopnosti pracovat s informacemi napříč celým portfoliem a zachytit alespoň část skrytých vzorců v datech. Výjimkou jsou nové produkty (1–5 měsíců), kde se rozdíly mezi přístupy zmenšují.
V tomto scénáři hraje klíčovou roli nedostatek dat a vyšší míra náhodnosti. Predikce je zde obecně méně spolehlivá bez ohledu na zvolený přístup.
V tomto projektu tak přestává být hlavní otázkou výběr modelu. Klíčová je samotná schopnost pracovat s nepravidelností a vysokým podílem nul.
Tento dataset ukazuje zásadně jiný problém než předchozí projekt – nejde o složitost vzorců, ale o samotnou existenci prodeje. Vysoký podíl nulových hodnot zásadně mění charakter predikce: modely zde neřeší pouze velikost, ale především to, zda k prodeji vůbec dojde.
Statistické metody i machine learning mají tendenci zjednodušovat chování dat a vracet se k průměru. Deep learning v tomto scénáři dosahuje lepších výsledků zejména díky schopnosti pracovat s informacemi napříč celým portfoliem a zachytit alespoň část skrytých vzorců.
Je zároveň důležité správně nastavit očekávání. U tohoto typu dat není realistické očekávat přesnou predikci jednotlivých období a to ani od pokročilých modelů. Prodeje se objevují nepravidelně a často bez jasného vzorce. Bez dostatečné historie a při takto vysoké míře variability je prakticky nemožné spolehlivě odhadnout, kdy přesně k prodeji dojde a v jakém objemu. To ale neznamená, že predikce nedává smysl.
Hodnota modelu zde není v přesném odhadu jednotlivých týdnů. Je ve schopnosti snížit míru nejistoty při plánování.
V dalším článku se podíváme na třetí typ datasetu, který kombinuje více dimenzí a přináší jinou vrstvu komplexity.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays