Jedním z klíčových faktorů, který se v praxi opakovaně ukazuje jako rozhodující, je délka dostupné historie. Právě ta často určuje, zda model dokáže zachytit trend a sezónnost, nebo zda se jeho predikce rozpadá. Tento problém je zásadní zejména v prostředí, kde se produktové portfolio neustále mění a nové položky vznikají bez dostatečné historie.
Pro lepší pochopení tohoto problému se podívám na konkrétní dataset, který dobře reprezentuje typický retailový scénář. Je na něm velmi dobře vidět, jak rozdílná délka historie napříč produkty ovlivňuje chování jednotlivých modelů.
Dataset obsahuje měsíční prodeje pro přibližně 15 000 produktů za období 4 let. Na první pohled působí dataset relativně jednoduše. Při detailnějším pohledu se ale ukazuje výrazná variabilita mezi jednotlivými produkty – zejména v délce historie a stabilitě prodejů.
Rozdíly jsou patrné i v objemech:
Základní charakteristika datasetu je shrnutá v následující tabulce:
| Parametr | Hodnota |
|---|---|
| Počet produktů | 15 000 |
| Frekvence dat | měsíční |
| Nejdelší historie | 48 měsíců |
| Nejkratší historie | 1 měsíc |
| Podíl období 1 - 6 měsíců | 2.7% |
| Podíl období 7 - 12 měsíců | 4.6% |
| Podíl období 13 - 24 měsíců | 6.6% |
| Podíl období 24+ měsíců | 86.1% |
| Průměrná velikost prodeje | 54.7 |
| Medián prodeje | 14 |
| Maximální prodej | 39 097 |
| Podíl nulových prodejů | 8.1% |
Z pohledu plánování jde o typický případ, který dobře ilustruje problémy, se kterými se modely v praxi setkávají.
Délka dostupné historie je jedním z klíčových faktorů ovlivňujících kvalitu predikce. Proto všechny testy probíhaly na podmnožinách datasetu rozdělených podle délky historie jednotlivých produktů – od celého portfolia až po položky s velmi krátkou historií.
Právě tato různorodost představuje hlavní problém – modely musí pracovat s produkty, které se chovají zcela odlišně, často s velmi omezeným množstvím dat.
Pro porovnání jednotlivých přístupů byla použita jednotná validační strategie, kdy byly modely trénovány na historických datech a testovány na následujícím období. Tento přístup odpovídá reálnému použití modelu, kdy predikujeme budoucnost na základě minulosti.
Výkon modelů byl hodnocen pomocí kombinované metriky vycházející z několika standardních ukazatelů přesnosti. Cílem nebylo optimalizovat jednu konkrétní hodnotu, ale získat robustní pohled na kvalitu predikce napříč různými typy produktů. Výsledná hodnota reprezentuje celkovou velikost chyby – čím nižší číslo, tím přesnější predikce. Důležité je ale vnímat ji v kontextu jednotlivých scénářů, protože rozdíly mezi modely se výrazně liší v závislosti na délce historie a charakteru dat.
Pro lepší interpretaci výsledků jsou jednotlivé scénáře dále rozděleny podle délky historie produktů.
Rozdíly mezi přístupy jsou zde relativně malé, a proto složitější modely nepřinášejí výraznou přidanou hodnotu z pohledu nákladů.
Modely mají dostatek dat pro zachycení trendu i sezónnosti, a proto zde fungují dobře i jednodušší statistické metody. Machine learning i deep learning sice dosahují o něco lepších výsledků, rozdíly se však projevují především u sezónních a promo položek, kde je chování méně stabilní.
V tomto scénáři proto složitější modely (DL) nepřinášejí zásadní přidanou hodnotu vzhledem ke své náročnosti.
Se zkracující se historií začínají být rozdíly mezi přístupy výraznější. Statistické metody postupně ztrácejí schopnost zachytit sezónnost, protože nemají dostatek dat. Machine learning si udržuje relativně stabilní výkon, zatímco deep learning začíná získávat výhodu díky schopnosti pracovat s komplexnějšími vztahy a kontextem.
Klíčovým důvodem těchto rozdílů je právě délka dostupné historie.
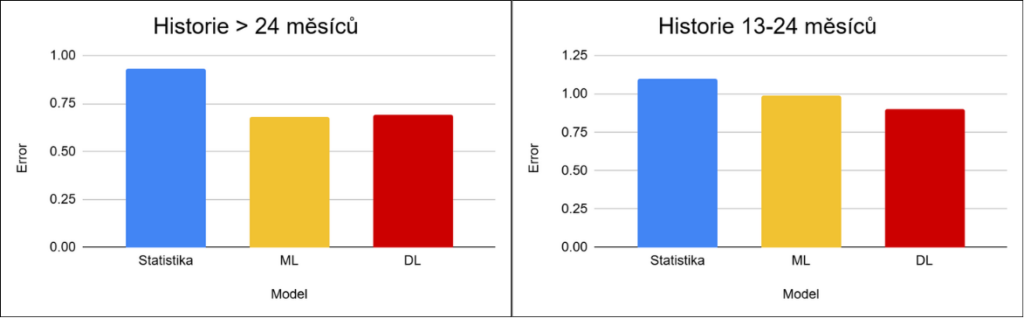
Nejnáročnější scénáře představují produkty s krátkou historií. V těchto případech mají všechny přístupy výrazně omezené množství informací, což vede k poklesu přesnosti napříč modely. Deep learning zde získává výhodu díky schopnosti hledat podobnosti mezi produkty na základě dalších charakteristik. I přesto však zůstává predikce velmi nejistá a její praktická využitelnost je omezená.
Hlavním problémem tak není pouze volba modelu, ale především nedostatek kvalitních dat.
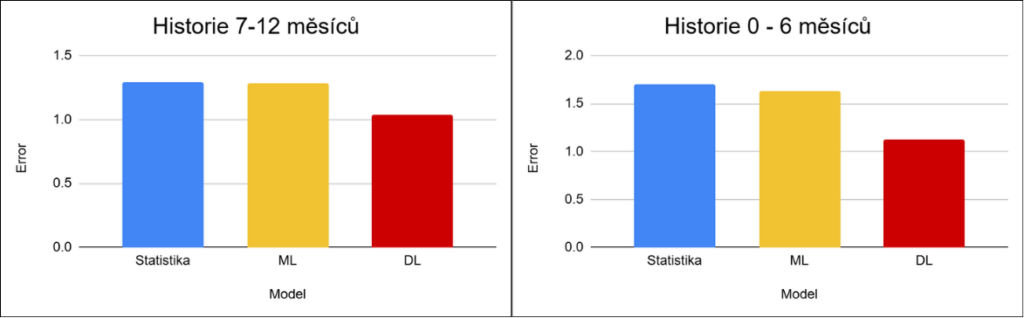
Předchozí výsledky ukazují rozdíly na úrovni celých skupin. Podívejme se nyní na konkrétní příklady, které lépe ilustrují chování jednotlivých přístupů v praxi. Černá křivka představuje reálné hodnoty, barevné křivky predikce jednotlivých přístupů.
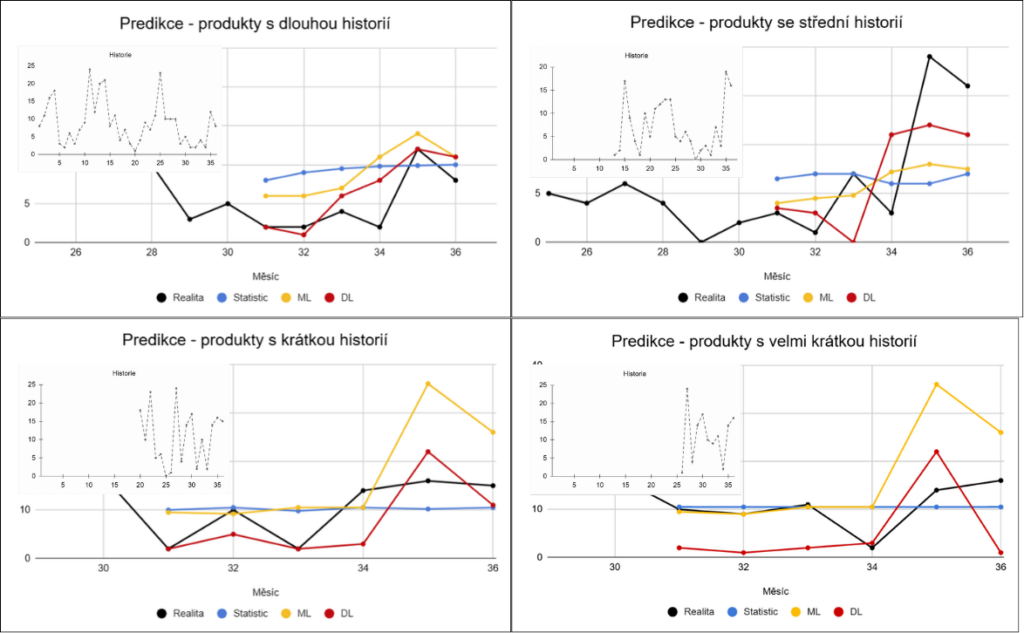
Tyto příklady dobře ilustrují rozdílné chování jednotlivých přístupů. Statistické přístupy mají tendenci predikce vyhlazovat a vracet se k průměru, což vede k podhodnocení špiček a přecenění slabších období. Machine learning reaguje na změny lépe, ale často se zpožděním. Deep learning dokáže zachytit komplexnější vzorce a rychleji reagovat na změny, zároveň však může být v některých případech citlivější na šum.
Tyto rozdíly se navíc výrazně mění v závislosti na délce historie – čím méně dat je k dispozici, tím více se projeví limity jednodušších přístupů.
Vedle délky historie existují i další faktory, které mají zásadní vliv na kvalitu predikce a často představují hlavní důvod selhání modelů v praxi.
Některé produkty vykazují výraznou sezónnost – typicky s opakujícími se špičkami během roku, například v období Vánoc. Predikce zde závisí na schopnosti modelu správně zachytit opakující se vzorce v čase. Při dostatečně dlouhé historii si s tímto problémem poradí i jednodušší přístupy. Jakmile je ale historie kratší nebo se sezónnost v čase mění, začínají tyto modely selhávat a rozdíly mezi přístupy se výrazně prohlubují.
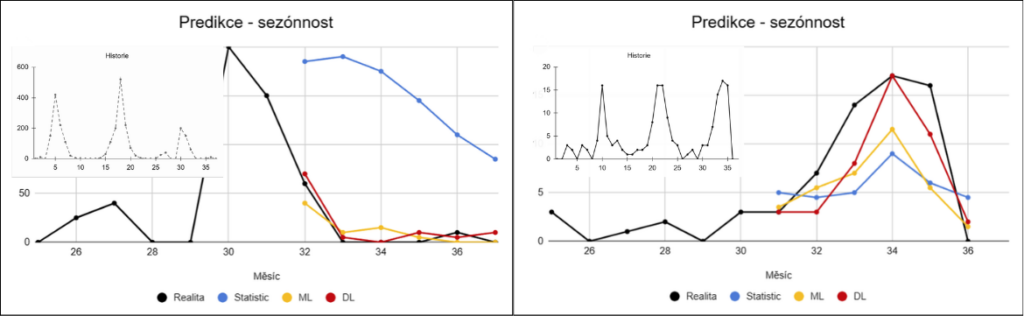
U části sortimentu se prodeje objevují nepravidelně, bez jasného vzorce. Náhodné výkyvy zanášejí do dat šum a ztěžují modelům rozlišení mezi skutečným trendem a náhodným chováním.
Jednodušší přístupy mají tendenci taková data zjednodušovat a vracet se k průměru. Složitější modely mají díky většímu množství parametrů a informací větší šanci zachytit alespoň část skrytých vzorců, i když ani zde nelze očekávat stabilní výsledky.
Specifickým případem jsou promo akce, které způsobují krátkodobé, výrazné nárůsty prodejů. Pokud model nemá informaci o tom, že se jedná o promo, vnímá tyto výkyvy jako šum.
Jednodušší přístupy pak tyto změny nedokážou správně interpretovat a často je buď ignorují, nebo na ně reagují se zpožděním. I pokročilejší modely zde naráží na limity, pokud nemají k dispozici relevantní vstupní informace.
Pokud jsou však tyto informace dostupné, mohou je složitější modely efektivněji využít díky schopnosti pracovat s větším množstvím vstupních proměnných a jejich vzájemnými vztahy.
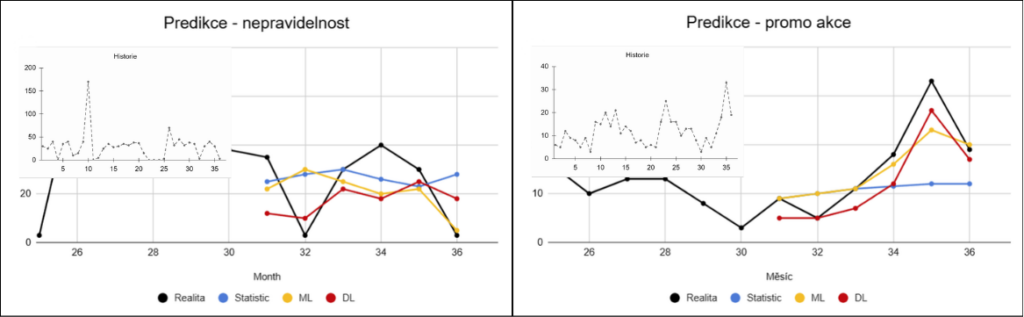
Tyto faktory se v praxi často kombinují, což výrazně zvyšuje komplexitu celého problému. Právě jejich souběh je důvodem, proč jednoduché modely v reálných scénářích často selhávají a proč rozdíly mezi přístupy narůstají.
Tento projekt ukazuje, že kvalita predikce není dána pouze volbou modelu, ale především charakterem dat.
Délka historie zásadně ovlivňuje, jak dobře model dokáže zachytit trend a sezónnost. U produktů s dostatečně dlouhou historií jsou rozdíly mezi přístupy relativně malé a jednodušší metody často postačují. S klesající délkou historie se však modely začínají výrazně rozcházet – statistické přístupy ztrácejí schopnost zachytit sezónnost, zatímco deep learning dokáže částečně kompenzovat nedostatek dat.
Zásadní roli přitom hrají i další faktory, jako je sezónnost a promo akce. Ty zvyšují komplexitu dat a bez odpovídajících vstupních informací představují pro modely významný problém bez ohledu na jejich typ.
Největší rozdíl mezi přístupy se tak neprojevuje v ideálních podmínkách, ale právě v situacích, které jsou v praxi nejčastější – tedy u produktů s omezenou historií a zároveň vysokou variabilitou způsobenou sezónností nebo promo akcemi.
V dalším článku se podíváme na dataset, kde většinu dat tvoří nulové prodeje – a kde se rozdíly mezi přístupy projeví ještě výrazněji.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays