V předchozích projektech jsem pracoval s daty, kde hlavním problémem byla délka historie nebo vysoký podíl nulových prodejů. Třetí projekt řeší odlišný scénář. Dataset obsahuje denní prodeje s dostatečně dlouhou historií pro všechny položky.
Hlavní výzvou zde nejsou chybějící data, ale vlivy, které prodeje systematicky deformují – zejména víkendy, svátky a rozdíly mezi lokalitami. Bez jejich správné interpretace selhávají i pokročilejší přístupy. Model tak neřeší nedostatek dat, ale schopnost pochopit, proč se data v čase mění.
Dataset obsahuje denní prodeje pro přibližně 1 800 kombinací za období 4,5 roku.
Rozdíly jsou patrné i v objemech:
Základní charakteristika datasetu je shrnutá v následující tabulce:
| Parametr | Hodnota |
|---|---|
| Počet kombinací (skupina/lokalita) | 1 800 |
| Frekvence dat | denní |
| Nejdelší historie | 1 688 dnů |
| Nejkratší historie | 118 dnů |
| Podíl období 1 - 6 měsíců | 1.9% |
| Podíl období 7 - 12 měsíců | 0.0% |
| Podíl období 13 - 24 měsíců | 3.7% |
| Podíl období 24+ měsíců | 94.4% |
| Průměrná velikost prodeje | 383.7 |
| Medián prodeje | 16.0 |
| Maximální prodej | 31 024 |
| Podíl nulových prodejů | 26.0% |
Dataset tak na první pohled nepůsobí jako extrémně složitý. Většina položek má dlouhou historii a nulové prodeje tvoří přibližně čtvrtinu dat.
Právě kombinace stabilní historie a externích vlivů vytváří zajímavý scénář – jednodušší modely mají dostatek dat, ale nemusí být schopné správně reagovat na změny způsobené kalendářními nebo lokalitními faktory.
Pro porovnání jednotlivých přístupů byla použita identická validační strategie jako v prvním projektu. Modely byly trénovány na historických datech a testovány na následujícím období.
Na rozdíl od předchozích projektů zde není hlavním problémem nedostatek historie ani extrémní množství nulových hodnot. Model zde musí správně reagovat na externí vlivy, jako jsou svátky nebo lokalita. Pokud je nezohlední, vede to k systematickým chybám v plánování – například pravidelnému podhodnocení nebo nadhodnocení poptávky.
Klíčové jsou následující faktory:
Na základě charakteru datasetu jsem očekával, že rozdíly mezi modely budou menší než v předchozích projektech. Výhodu by však měly mít přístupy, které dokážou pracovat s externími vstupy.
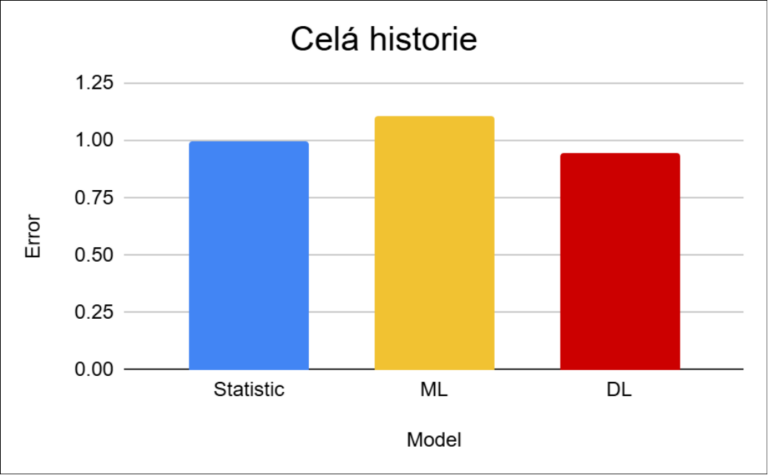
Výsledky ukazují, že rozdíly mezi přístupy jsou v tomto scénáři relativně malé. Deep learning dosahuje nejlepšího výsledku, přibližně o 5 %. Důvodem je schopnost pracovat s externími vstupy, jako jsou svátky nebo lokalita.
Statistické metody si vedou překvapivě dobře, protože dataset obsahuje stabilní historii a výrazné sezónní vzorce. Překvapivé jsou horší výsledky machine learningu, kdy bych očekával výsledky na úrovni statistických modelů nebo lepší. Důvodem může být omezená schopnost těchto modelů pracovat s komplexní kombinací kalendářních a lokalitních faktorů.
Rozdíl na úrovni přibližně 5 % je výrazně menší než v předchozích projektech, kde dosahoval desítek procent. To potvrzuje, že u stabilních datasetů s dostatečnou historií přestává být volba modelu klíčovým faktorem.
I když metriky ukazují velmi podobné výsledky napříč modely, detailní pohled na jednotlivé produkty ukazuje částečně odlišné chování. Jednodušší modely mají tendenci vracet predikci k průměru. U datasetu s větším podílem nenulových hodnot se tento problém v agregovaných metrikách často ztratí. Deep learning naopak lépe reaguje na krátkodobé změny a dokáže zachytit výkyvy, které jsou pro plánování klíčové.
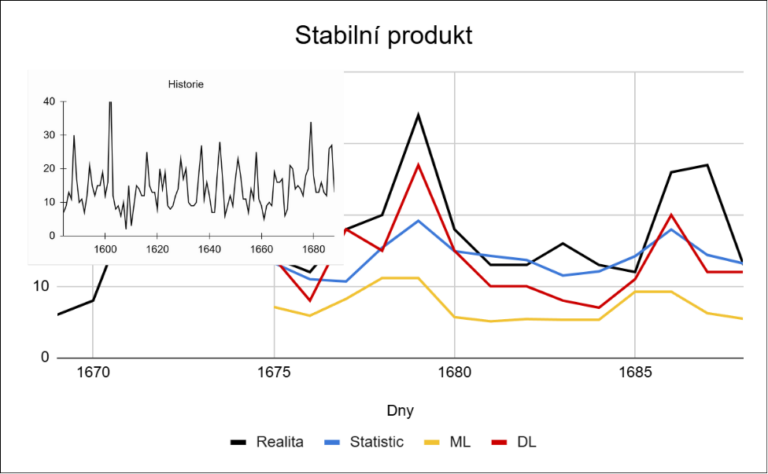
Na stabilním produktu s rostoucím trendem fungují všechny přístupy relativně dobře. Rozdíl je především v reakci na výkyvy:
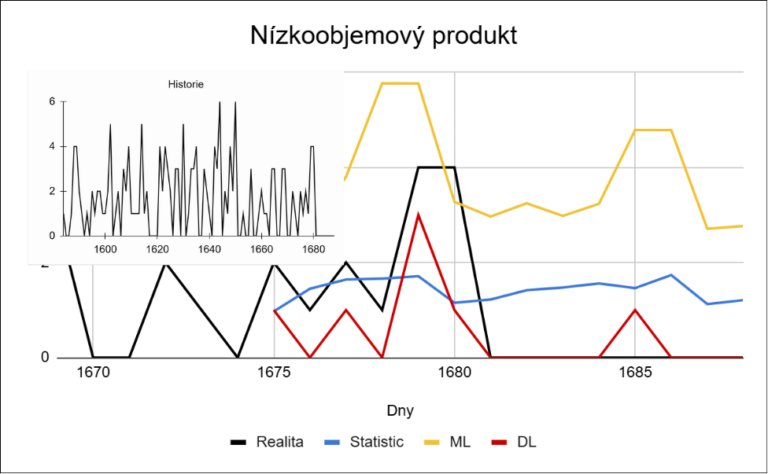
U nízkoobjemových produktů jsou rozdíly mezi modely větší. Důvodem je vysoký podíl nulových nebo nízkých hodnot, které tlačí predikce směrem k průměru. Jednodušší modely mají problém správně odhadnout výskyt prodeje. Deep learning v tomto projektu nepředpovídá pravděpodobnost prodeje (jako v projektu 2), ale i tak dokáže lépe zachytit změny v objemu.
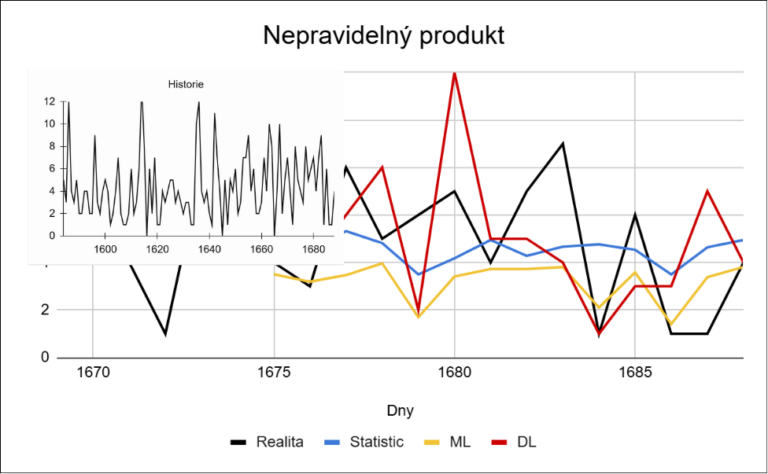
U nepravidelných produktů přesnost všech modelů klesá. Jednodušší přístupy mají tendenci stabilizovat predikci kolem průměru, což vede ke ztrátě informací o skutečném chování. Deep learning dokáže lépe reagovat na změny, ale ani zde nelze očekávat stabilní a přesnou predikci.
Agregované metriky ukazují minimální rozdíly mezi modely. Při pohledu na jednotlivé produkty je ale realita odlišná. Extrémní chyby se v agregovaných metrikách snadno ztrácí. Model, který selhává u menší části produktů, může v průměru působit stejně dobře jako model, který je stabilnější.
Při vyhodnocení pouze na specifických produktech se rozdíly mezi přístupy výrazně zvětšují. To znamená, že i při podobných agregovaných výsledcích mohou mít modely v praxi výrazně odlišný dopad – zejména u klíčových produktů nebo výkyvů.
Ve srovnání s předchozími projekty se zde ukazuje odlišný typ problému. Zatímco v předchozích scénářích hrála klíčovou roli dostupnost dat nebo jejich struktura, zde rozhoduje schopnost modelu správně interpretovat externí vlivy. V tomto projektu jsou data relativně stabilní a dobře popsaná. Rozdíly mezi modely jsou proto výrazně menší než v předchozích projektech. Statistické přístupy zde dosahují překvapivě dobrých výsledků. Klíčovým problémem zde není dostupnost dat, ale schopnost modelu reagovat na jejich změny v čase.
Při detailnějším pohledu se ale ukazuje, že jednodušší modely selhávají u konkrétních produktů, zejména při výkyvech. Deep learning dokáže díky práci s externími vstupy lépe zachytit strukturu dat a reagovat na změny. V praxi to ale znamená přesnější reakci na změny, které mohou ovlivnit zásoby.
Hlavní otázkou tak není, který model je nejlepší, ale zda přínos přesnosti odpovídá vyšší komplexitě řešení.
V dalším článku zhodnotíme jednotlivé projekty a podíváme se na to, jestli a jak lze využít pokročilé deep learning modely bez vlastního implementačního týmu.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays