Most companies outside large enterprises still plan demand the same way they did years ago – using Excel, simple models, and human experience.
It works for a while. The problem appears when reality becomes more complex. Seasonality changes, promotions distort demand, new products have no history, and knowledge often exists only in people’s heads – people who eventually leave. The result? Inaccurate forecasts, excess inventory, or stockouts.
Today’s landscape is heavily influenced by AI, especially LLMs. It is often claimed that these models will transform forecasting just as they transformed text processing or programming.
But is that really the case?
LLMs work extremely well with text, interpretation, and data analysis. However, time series forecasting is a different type of problem. It requires models that understand temporal dependencies, seasonality, and data structure.
So the question is not whether to use AI. The question is how to use it correctly – and which approach makes sense in real-world environments.
That is exactly what this article focuses on. Based on real data, I compare statistics, machine learning, and deep learning – showing where each approach works, where it fails, and what it means in practice.
And most importantly – whether advanced models make sense even for smaller companies.
Before looking at the approaches themselves, it is important to understand the data. In practice, there is no such thing as a “typical” problem. Every dataset has its own characteristics, which strongly influence model performance. Projects Used in Testing:
Project 1
Project 2
Project 3
Factors that significantly impact forecasting quality:
These factors determine which model will succeed – and which will fail.
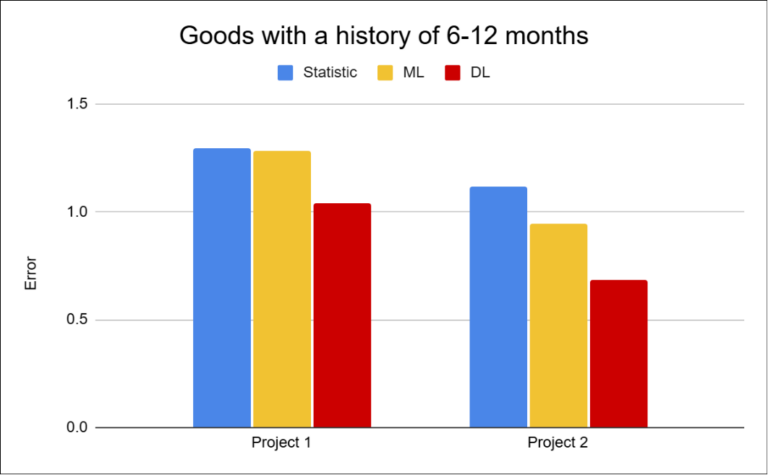
Alongside data characteristics, the length of history also proved to be a critical factor. Products with long histories tend to behave relatively stable, while new or short-lived items are significantly harder to forecast.
More data does not automatically mean better predictions. Longer histories often include more noise and irregularities, which can make learning more difficult for models.
The core hypothesis was simple:
Three approaches were compared:
For comparison, a unified validation strategy was used. Models were trained on historical data, with the last six periods reserved for validation. Each approach was optimized independently to achieve the best possible performance within its respective setup.
Real-world datasets are rarely clean. They usually combine stable, seasonal, and irregular sales, along with noise and short histories.
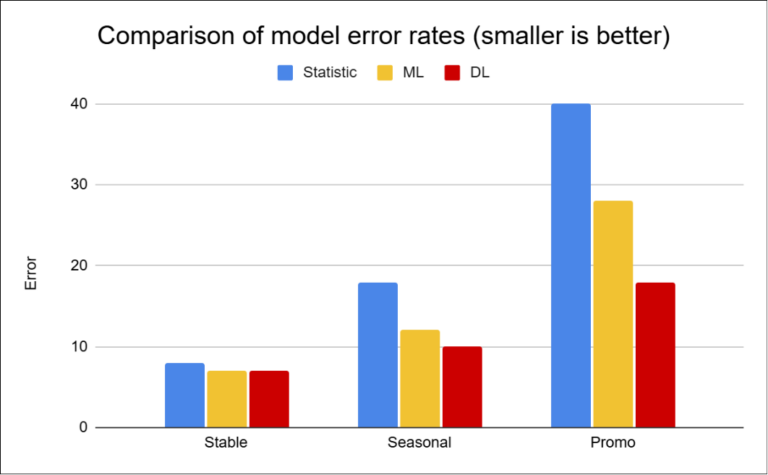
The results show a clear pattern:
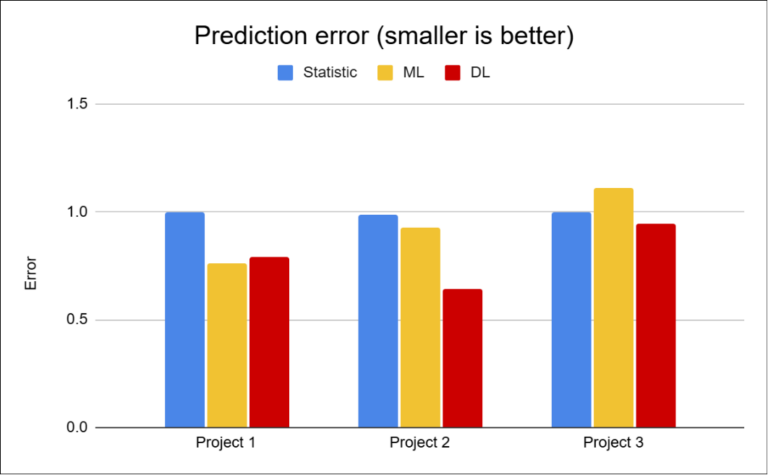
Project 2 shows that datasets with a high number of zero and irregular sales represent a major challenge for traditional approaches.
In contrast, Project 3 demonstrates that in more stable scenarios, simpler methods can be sufficient.
However, this changes significantly for items with shorter history. It is precisely in these cases that the differences between approaches become most apparent — simple models lose accuracy, while deep learning often manages to maintain significantly better performance.
The difference between models is not just about percentages. It is about how much inventory you hold — and how many customers you lose. The following overview shows the business impact of different approaches based on the tested scenarios:
| Product Type | Improvement | Inventory Impact | Stockout Impact |
|---|---|---|---|
| Stable | 1–3 % | Minimal | None |
| Seasonal | 8–12 % | inventory reduction 3–5 % | Fewer stockouts |
| Promo / Irregular | 20–40 % | inventory reduction 10–20 % | Fewer stockouts, higher revenue |
These values are based on tested scenarios and practical experience. Model selection should therefore not be universal, but depend on the characteristics of a specific part of the portfolio. In practice, this means that different types of products require different approaches. While stable items with long history can be effectively forecasted using simpler methods, seasonal, irregular, or new products expose the limits of these approaches — and the value of more complex models increases significantly.
The key is not to find one “best” model, but to choose the right approach for a specific type of problem.
The results show when each approach makes sense.
The difference between approaches is not just visible in metrics, but in how much capital you hold in inventory and how many orders you fail to fulfill.
Deep learning is often not used in practice because every change requires intervention in the solution — which means additional time and cost. However, once you introduce a unifying layer over this process, the way of working changes fundamentally. Instead of making major changes to the solution, you adjust parameters and systematically test different variants. This can reduce development time from months to weeks.
The more complex and less predictable the data, the bigger the difference between approaches — and the more sense it makes to use deep learning. At the same time, without proper setup, its real-world impact can be close to zero.
In the following articles, I will focus on specific projects and show how different approaches behave in practice. In the final part of the series, I will break down the metrics, model setup, and practical implementation experience in more detail.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays