Většina firem mimo velké společnosti dnes plánuje poptávku podobně jako před lety – pomocí Excelu, jednoduchých modelů a zkušeností lidí.
Nějaký čas to funguje, problém nastává ve chvíli, kdy se realita začne chovat složitěji. Sezónnost se mění, slevové akce deformují poptávku, nové produkty nemají historii a znalosti často zůstávají pouze v hlavách lidí, kteří postupně odcházejí. Výsledkem jsou nepřesné predikce, nadzásoby nebo naopak vyprodané položky.
Aktuální doba je silně ovlivněná AI, zejména LLM modely. Velmi často se přitom objevují tvrzení, že tyto modely posunou oblast predikcí podobným způsobem, jako již zásadně proměnily práci s textem nebo programováním.
Je to ale opravdu tak?
LLM modely velmi dobře fungují při práci s textem, interpretaci výsledků a analýze dat. Samotná predikce časových řad je ale jiný typ problému – vyžaduje modely, které pracují s časovou závislostí, sezónností a strukturou dat.
Otázka tedy není, jestli AI použít. Otázka je, jak ji správně kombinovat – a jaký přístup dává smysl v reálném prostředí. A právě na to se v tomto článku zaměřuji. Na reálných datech porovnávám statistiku, machine learning a deep learning a ukazuji, kde jednotlivé přístupy fungují, kde naopak narážejí na své limity a co to znamená v praxi.
A především – jestli mají pokročilé modely reálné využití i pro menší společnosti.
Než se podíváme na samotné přístupy, je důležité pochopit, s jakými daty vlastně pracujeme.
V praxi totiž neexistuje jeden „typický“ problém. Každý dataset má své specifika, která zásadně ovlivňují, jak dobře jednotlivé přístupy fungují.
V rámci testování jsem pracoval se třemi rozdílnými projekty:
Projekt 1
Projekt 2
Projekt 3
Faktory, které mají zásadní vliv na kvalitu predikcí jsou:
Tyto faktory rozhodují o tom, jaký model bude fungovat a který naopak začne selhávat. Vedle typu dat se jako zásadní faktor ukázala také délka historie. Produkty s dlouhou historií se chovají relativně stabilně. Naopak u nových nebo krátkodobých položek je predikce výrazně obtížnější.
Více dat neznamená automaticky lepší predikci. Delší historie často obsahuje více šumu a nepravidelností, které modelům komplikují učení.
Základní hypotéza byla jednoduchá:
Pro srovnání jsem použil tři základní přístupy:
Pro porovnání byla použita jednotná validační strategie, kde byly modely trénovány na historických datech s výjimkou posledních 6 období, která sloužila k validaci.
Každý přístup byl optimalizován samostatně s cílem dosáhnout co nejlepšího výkonu v daném scénáři.
V praxi se málokdy setkáváme s ideálními daty. Typický dataset obsahuje kombinaci stabilních, sezónních i nepravidelných prodejů, často doplněnou o chyby v datech nebo produkty s krátkou historií.
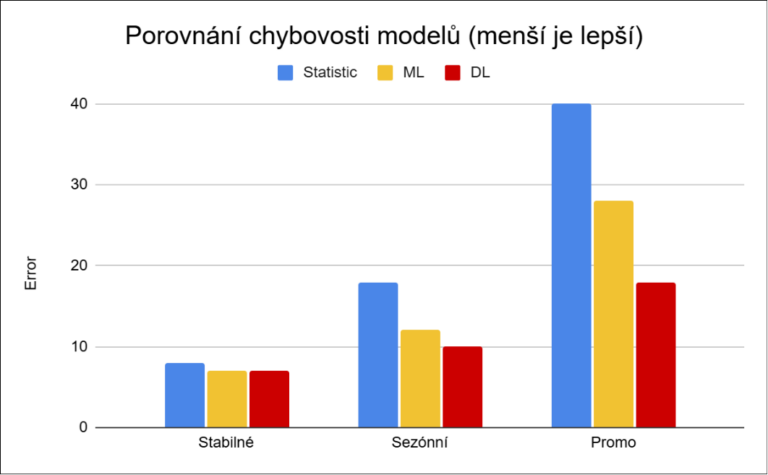
Výsledky experimentu ukazují poměrně jasný trend:
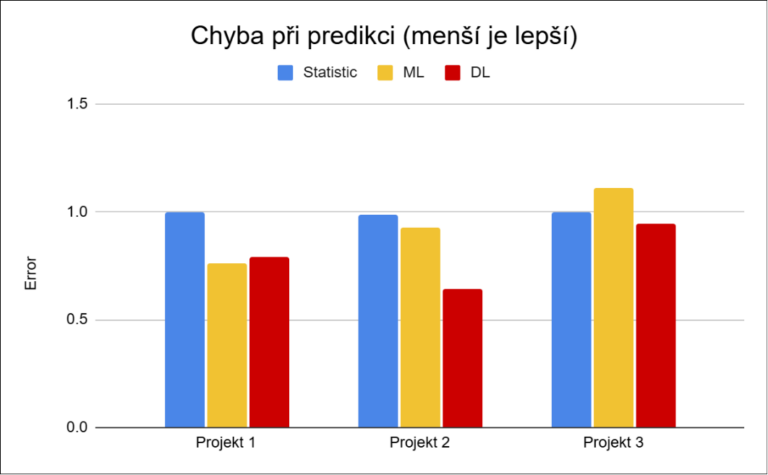
Projekt 2 ukazuje, že data s velkým množstvím nulových a nepravidelných prodejů představují pro klasické přístupy zásadní problém. Naopak projekt 3 ukazuje, že u stabilnějších scénářů mohou být jednodušší metody dostatečné.
To se ale výrazně mění u položek s kratší historií. Právě zde se rozdíly mezi přístupy nejvíce projevují – jednoduché modely ztrácejí přesnost, zatímco deep learning si často dokáže udržet výrazně lepší výsledky.
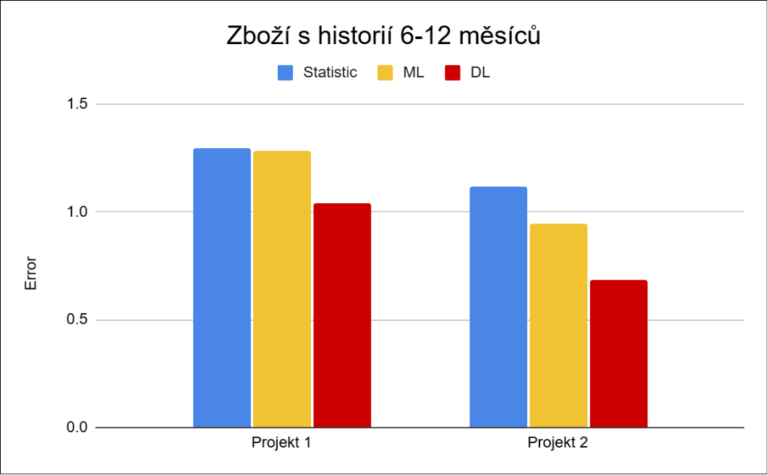
Rozdíl mezi modely není jen v procentech. Rozdíl je v tom, kolik toho držíte na skladě – a kolik zákazníků si necháte utéct. Následující přehled ukazuje business rozdíly mezi přístupy na základě testovaných scénářů:
| Typ sortimentu | Zlepšení přesnosti | Dopad na zásoby | Dopad na vyprodanost |
|---|---|---|---|
| Stabilní | 1–3 % | minimální | žádný |
| Sezónní | 8–12 % | snížení zásob 3–5 % | méně výpadků v sezóně |
| Promo / nestabilní | 20–40 % | snížení zásob 10–20 % | méně výpadků, vyšší tržby |
Hodnoty vycházejí z testovaných scénářů a zkušeností z praxe. Volba modelu by proto neměla být univerzální, ale závislá na charakteru konkrétní části portfolia.
V praxi to znamená, že různé typy produktů vyžadují odlišný přístup – zatímco stabilní položky s dlouhou historií lze efektivně predikovat pomocí jednodušších metod, u sezónních, nepravidelných nebo nových produktů začínají tyto přístupy selhávat a přínos komplexnějších modelů výrazně roste. Klíčové tedy není najít jeden „nejlepší“ model, ale zvolit správný přístup pro konkrétní typ problému.
Výsledky ukazují, kdy který přístup dává smysl. .
Rozdíl mezi přístupy se neprojevuje jen v metrikách, ale v tom, kolik kapitálu držíte na skladě a kolik objednávek nedokážete pokrýt.
Deep learning se v praxi často nepoužívá, protože každá změna znamená zásah do řešení – a tím pádem čas a náklady navíc.
Jakmile ale máte nad tímto procesem vrstvu, která ho sjednocuje, mění se způsob práce zásadně Místo zásadních změn v řešení jen upravujete parametry a systematicky testujete různé varianty. To umožňuje zkrátit vývoj z měsíců na týdny.
Čím komplexnější a méně předvídatelná data, tím větší rozdíl mezi přístupy – a tím více dává smysl deep learning. Zároveň ale platí, že bez správného nastavení může být jeho přínos v praxi nulový.
V dalších článcích se zaměřím na konkrétní projekty a ukážu, jak se jednotlivé přístupy chovají v praxi. . Na závěr série pak rozeberu konkrétní metriky, technické nastavení modelů a praktické zkušenosti z implementace.
IČO: 172 28 018
DIČ: CZ 172 28 018
Data Box ID: ykwdnxf
sales@neebile.cz
Jičínská 226/17, Praha, Žižkov, PSČ 130 00 Česká republika
(910) 658-2992
© 2025 Vytvořeno DigitalWays