Predikce zásob pomocí AI
8. Generalizace – zapojení položek s neúplnou historií
Test s celým datasetem
V minulé kapitole jsme ověřili, že model zvládá „bezchybně“ těch 70 % sortimentu, které mají kompletní 36 měsíční historii. Nastal čas pustit jej na celý dataset a zjistit, co se stane, když do hry vstoupí i produkty s kratšími nebo žádnými daty.
| Délka historie | Počet položek | Podíl na sortimentu |
|---|---|---|
| 36 měsíců (plná historie) | 10105 | 70.00% |
| 12–35 měsíců | 2668 | 18.00% |
| méně než 12 měsíců | 1211 | 8.00% |
| bez historie | 519 | 4.00% |
Všechny následující experimenty běží na modelu, který jsem postavil v předchozích dílech – tzn. s kompletním feature-engineeringem a omezením extrémů. Opět používám scénář 2 (trénink 33 měsíců / validace poslední 3 měsíce).
Zvolil jsem tři tréninkové varianty. Validace je vždy nad celým datasetem.
| Varianta | Co se použije do tréninku | Nových položek k validaci |
|---|---|---|
| A – plná historie | Pouze položky s kompletní historií | 468 |
| B – min. 1 měsíc historie | Všechny SKU, které mají aspoň 1 historický záznam | 73 |
| C – bez omezení | Úplně všechny položky (včetně těch bez historie) | 0 |
Poznámka: Například ve variantě Plná historie (A) bylo při validaci nalezeno 468 nových položek, které model při tréninku neviděl.
Co sleduji:
- Globální metriky (R², WAPE, RMSE, …) mezi variantami A, B, C.
- Dopad na položky s plnou historií – jak se mění metriky po přidání „chudších“ položek.
- Chování nových/krátkých položek– jestli transfer z “bohatých” sérií pomůže, nebo jestli predikce dál sklouzává k nule či náhodným skokům.
| Metrika | Plná historie | Jakákoliv historie | Min. 1 měsíc historie | |||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 41.0748 | 133.7093 | 38.4147 | 93.4879 | 34.6338 | 58.0287 |
| RMSE | 48.8867 | 24.5721 | 57.3472 | 23.2029 | 35.4181 | 18.5031 |
| R² | 0.7952 | 0.7408 | 0.8511 | |||
| MAPE | 131.7516 | 70.8846 | 68.2377 | |||
| ROBUST | 0.4741 | 158.7209 | 0.4785 | 78.5382 | 0.5312 | 77.5052 |
| STABLE | 0.5013 | 0.4613 | 0.3681 | |||
Shrnutí čísel:
- Trénink jen s plnou historií (levý sloupec), tedy všechny položky měli kompletní historii. Predikce silně selhává na položkách, které model nikdy neviděl. Item-WAPE i MAPE letí přes 130 %.
- Trénink na všech položkách, včetně těch bez historie (prostřední sloupec), globální metriky nezlepší a naopak zvedá RMSE. Trénink na položkách bez historie zanáší velký šum.
- Optimální varianta je trénink s minimálně 1 měsícem historie (pravý sloupec) – výrazně stahuje chybu dolů a zároveň drží vysoké R². Tuhle variantu jsem zvolil jako novou baseline.
Vizuální kontrola
Dalším krokem byla vizuální kontrola, opět na oblíbených problematických položkách, navíc rozšířené o položky s krátkou a nulovou historií.
Zobrazené modely:
- 🔴 Model jen s plnou historií
- 🟢 Model i s nulovou historií
- 🟣 Model s min. 1 měsícem historie
Poznámka: Z důvodu přehledu o délce historie je zobrazeno všech 36 měsíců
U položek s plnou historií jsou predikce všech tří modelů téměř totožné. Znamená to, že i když do tréninku přimícháme položky s chybějícími měsíci, síť si poradí—díky feature –weight– dokáže „přeskočit“ prázdná místa a vzor nezkreslí. Modely trénované na datech s různě dlouhou historií predikovaly vyšší (lepší) vrcholy u sezónních položek než model postavený jen na plné historii. Kratší série zřejmě dodaly dodatečný kontext, díky němuž síť odhadla sezónní špičky odvážněji — a v mnoha případech i přesněji.
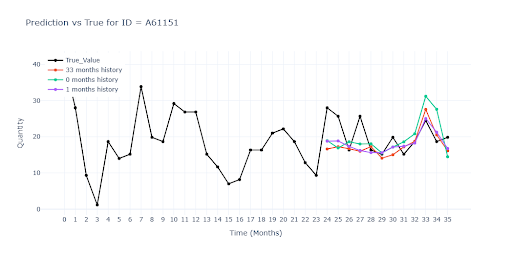

U položek s částečnou historií červený model výrazně propadl. Neměl k dispozici jediný reálný záznam dané položky, tudíž ani představu o jejím typickém obratu. Musel hádat čistě podle podobnosti s jinými produkty.
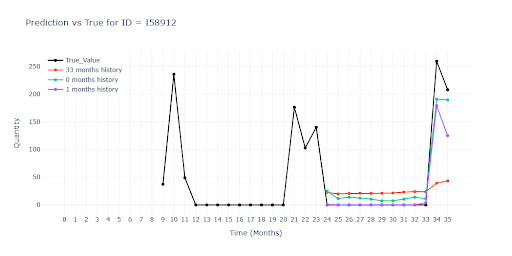

Podobný propad vidíme i u položek s velmi krátkou historií. Červený model se opět neměl čeho chytit. Ostatní dva modely sice také pracují jen s velmi krátkou historií, ale dokáží z ní odhadnout alespoň velikost obratu položky a přiblížit se reálu.
Na druhém obrázku je navíc dobře vidět, jak zelený a fialový model „vytahuje“ predikci z podobných SKU: i bez vlastní historie vystřelí prodej v druhém měsíci nahoru, protože obdobné produkty ve stejné skupině vykazují stejný vzor. Model tedy správně využil transfer znalostí z bohatších sérií, místo aby sklouzl k nule.
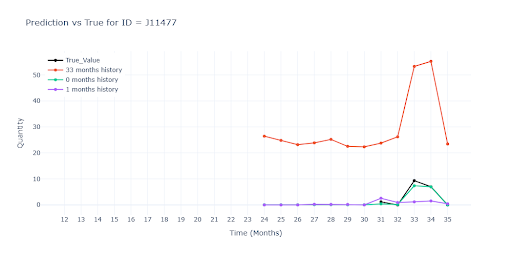
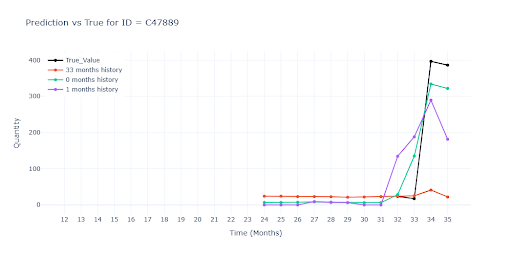
Kde není jediný historický záznam, jsou predikce už spíše odhadem „do prázdna“. Modely bez reálného scalu sklouznou k jakémusi průměru segmentu – u některých položek to znamená hrubé podstřelení, u jiných naopak přestřelení. Bez alespoň jednoho skutečného prodejního bodu zůstává výsledek hodně nečitelný.
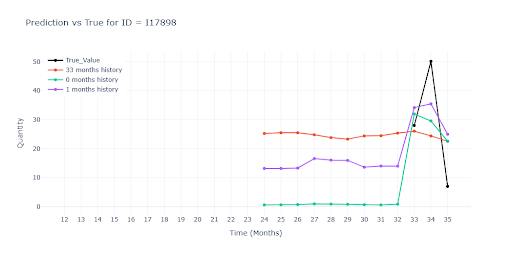
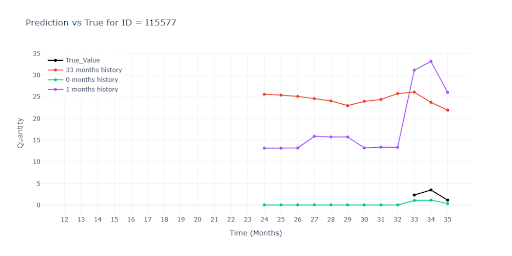
Jak si model vede podle délky historie
Pro detailnější pohled jsem vytvořil validaci pro pět různých scénářů podle délky historie položky. Níže uvádím hlavní postřehy – metriky jsou počítané už jen pro model trénovaný na položkách s minimálně jedním měsícem historie (zelená linka na předchozích grafech).
| Metrika | Celý dataset 100% položek | 36 měsíců 72% položek | 12-35 měsíců 18% položek |
|||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 34.6338 | 58.0287 | 33.4331 | 45.3934 | 36.5081 | 49.183 |
| RMSE | 35.4181 | 18.5031 | 38.1581 | 19.3561 | 23.4648 | 13.58 |
| R² | 0.8511 | 0.8535 | 0.7525 | |||
| MAPE | 68.2377 | 61.9222 | 67.8013 | |||
| ROBUST | 0.5312 | 77.5052 | 0.5282 | 62.6903 | 0.5365 | 66.6689 |
| STABLE | 0.3681 | 0.3505 | 0.4093 | |||
| Metrika | 6-12 měsíců 4% položek | 1-6 měsíců 4% položek | bez historie 2% položek |
|||
|---|---|---|---|---|---|---|
| Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | Hodnota (ALL) | Hodnota (Item) | |
| WAPE | 37.7617 | 55.3109 | 56.1651 | 61.0081 | 117.1288 | 884.835 |
| RMSE | 36.3108 | 11.9183 | 46.4892 | 34.9088 | 45.6377 | 33.9161 |
| R² | 0.7767 | 0.5277 | -0.0826 | |||
| MAPE | 69.1417 | 98.2678 | 636.876 | |||
| ROBUST | 0.5478 | 69.4062 | 0.5247 | 105.5108 | 0.4238 | 940.0516 |
| STABLE | 0.4296 | 0.5151 | 1.3529 | |||
Shrnutí čísel:
- Stabilita napříč historií: Model drží velmi podobné metriky až do kategorie 6 – 12 měsíců. Znamená to, že si dokáže poradit i s neúplnou minulostí. Rozdíl je v metrice R², způsobený chybějící historií.
- Nižší RMSE u 12–35 a 6–12 měsíců: Tyto položky jsou středně-obrátkové, absolutní odchylky jsou tedy menší, což RMSE stahuje dolů.
- Krátká historie: Pod hranicí šesti měsíců už metriky začínají padat – modelu chybí historie, ale stále se hodnoty drží v rozumných mezích. Bez dostatečné znalosti typickém obratu se model rozhoduje jen podle podobnosti se skupinou a chyby rychle rostou.
- Nulová historie: Výsledné metriky jsou výrazně zkreslené — model se opírá o skupinové znaky, ale chybí mu konkrétní kontext pro danou položku.
Mise „krátká historie“
Bylo zřejmé, že se musím zaměřit hlavně na položky s krátkou historií. U zcela nových položek, bez jediného prodejního záznamu a bez znalosti typického obratu, model není schopen nic „uhodnout“. Proto jsem si stanovil praktickou hranici: musí existovat alespoň jeden měsíc reálného prodeje. Z tohoto jediného bodu model načte velikost obratu a zbytek vzoru si „dovytáhne“ z podobných položek v segmentu – k tomu slouží skupiny a embedding vektory.
Pro dosažení tohoto cíle jsem přistoupil k testování dvou přístupů:
- Skupinové features – každá položka patří do segmentu a dostává vlastní embedding vektor. Chci přidat signály, které zvýrazní chování celé skupiny (průměrný obrat, sezónnost segmentu,…).
- Syntetická historie – u novinek generuji „warm-up“ období: prvních pár měsíců vyplním odhadem na základě podobných SKU. Tato syntetická data se použijí pouze pro výpočet features — model díky nim získá alespoň hrubý signál o tvaru křivky (trend, sezónnost), aniž bych ovlivnil trénink cílových hodnot.